CSC/ECE 517 Fall 2010/ch3 3j cj
Introduction
Object Relational Mapping is used to map object oriented programming objects to Relational Databases (e.g. SQL, Sybase, Oracle etc.). Object Relational Mapping is actually a programming technique to convert incompatible types between objects. ORM deals with how objects are stored in Relational Databases as scalar values. Object Relational Mapping creates a virtual object database where the programming language can interact directly. The mapping tools are used to map objects onto the databases.
Here database objects appear as programming language objects.

Why Objects and Relational Databases?
Relational Databases and Object-oriented paradigms are extensively used because they have a lot of advantages.
- Relational Databases are indispensable because:
- Flexible and robust approach to data management.
- Relational databases are used extensively in software development.
- Object-Oriented models are indispensable are because:
- Business logic can be implemented easily.
- Allows for use of design patterns and concepts like polymorphism.
- Improves code reuse and re-usability.
Persistence in Object-oriented applications
In an object-oriented application, persistence allows an object to outlive the process that created it. The state of the object may be stored to disk and an object with the same state re-created at some point in the future. This application isn’t limited to single objects—entire graphs of interconnected objects may be made persistent and later re-created in a new process. In order to achieve persistence, the objects need to be stored in a database and the database that we intend to use is a Relational Database.
persistence in various layers(http://www.objectarchitects.de/ObjectArchitects/orpatterns/)
Why mapping?
There is a impedance mismatch between Objects and relations. The object-oriented paradigm is based on software engineering principles. The relational paradigm is based on mathematical principles. So the software's that are built based on these two paradigms can’t work seamlessly with each other as the basic principle contradicts.
The common impedance mismatches between the object-oriented paradigm and relational paradigm are:
- Conflicting type systems.
- Conflicting design goals.
- Database system focuses specifically on the storage and retrieval of data, whereas an object system focuses specifically on the union of state and behavior of the objects.
- Conflicting architectural styles.
- Relational databases assume that the data is stored on the network and the objects are accessed through a remote connection. But object oriented paradigm performs inefficiently when used on a distributed system and conflicts directly.
- Differing structural relationships.
- Relational data stores the data as relations between tuples and tuple sets. Object-oriented systems treat entities in terms of class, behavior and state. Databases use foreign keys for relationships while Object-oriented systems use references between objects to identify the relationships.
- Differing identity constructs.
- The object-oriented system uses references to the objects or pointers to identify objects. The databases use primary key and keys identity constructs.
- Transactional boundaries.
- The object systems do not set any boundaries while interacting with other objects. But the database systems should set particular boundaries while dealing with multi-users.
- Query/access capabilities.
- RDBMS makes use of SQL which is a declarative language based on mathematical logic. But when accessing objects they need to be accessed object by object. This is termed as a problem when the data is distributed across the system.
Objects can’t be directly saved and retrieved from databases. Objects have identity, state and behavior along with their attributes (i.e. data), while relational databases can store only scalar values (data). ORM reduces the code to be written.
Mapping of Objects
The attributes of a class are mapped to the relational database. Each attribute can map to zero or more columns in the relational database. The attributes are stored in the database, but not all attributes are persistent. So while mapping, we need to decide which objects are persistent and which we do not need after the end of execution.
The three common types of mappings from tables to objects and back again are:
- Direct Mapping
- Merge Mapping
- Split Mapping
Here we take an example of employee and address class. Considering various factors like persistence and attributes we can see the different types of mappings in the above figure. In direct mapping the attributes are stored directly as scalar values in the database. In merge mapping, the attributes are stored according to their tables by splitting them. In split mapping, the objects are mapped after splitting them and adding to a related class.
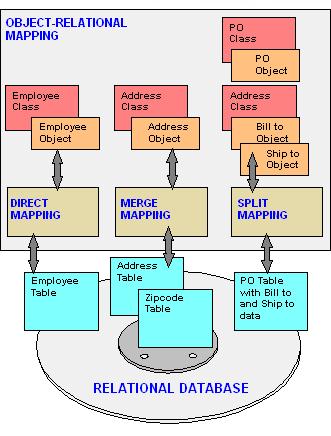

Considering the example, the employee object is stored in the employee table directly and so we can apply direct mapping. The address object attributes need to be stored in two different tables and in retrieval we need to retrieve them from two tables, so here merge mapping is performed. The bill_to and ship_to objects need to be stored in a different class and so the attributes are split from address object and stored to PO object to be stored in PO class. The image is taken from (http://www.answers.com/topic/object-relational-mapping)
Mapping various object relationships?
The object and the relational databases are updated accordingly so that there is no mismatch and the data is updated correctly. The various types of relationships(http://www.agiledata.org/essays/mappingObjects.html) where we update the tables are:
One-to-one relationships
In a one-to-one relationship one object references another object directly. When an object holds a contained reference to another object, it can create and delete its contained object. So when the holder of the contained object is manipulated (inserted, updated or deleted) then the referenced object is also updated automatically.
One-to-many relationships
The two different forms of one-to-many relationships are aggregation and association. Aggregation is an owned relationship where the owner class has an owned collection attribute and the owned class holds a direct reference to the owned class with a reference attribute. The owned class relationship is implemented using the foreign key concept. So when an object is updated the various related objects are updated using the reference to the foreign key. In an association the object references only the objects but does not own them, so we cannot modify the contents of the referenced attributes. Here the object uses a referenced collection attribute instead of an owned collection attribute. A Referenced Collection attribute can handle the association in the database by using either an embedded foreign key column or a join table.
Many-to-many relationships
This is a bi-directional one-to-many relationship. A referenced collection attribute is defined in each of the classes and in the corresponding relative model, a many-to-many relationship is defined using a foreign key or table join.
Example

In the above example each user has a password and has a one-to-one relationship. Each user can edit his password and only the password table gets updated. The user and posts has a one-to-many relationship and the posts and comments also have a one-to-many relationship. Here the user object has a reference to the password object and when the password is edited, the password table is updated automatically. The user has his own posts and this is an aggregation because the user owns his posts and has an owned collection attribute. The posts have many comments and just reference the comments but do not own them. A reference collection attribute is used to store them in the table.
Drawbacks
Object Relational Mapping tools fail to perform efficiently during deletion of data from Relational Databases and even simple joins.
Object Relational Mapping in Ruby
Active Record is an implementation of Object Relational mapping in Ruby. It connects objects and database tables to create a persistent domain model where logic and data co exist together. It is defined as
“An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.”
It is the default Object relational model used on Ruby on Rails. Objects in Active Record do not have their own attributes but infer from the database table definitions they are linked to. Adding, Removing or changing attributes and their types are done to the database and are instantly reflected in the Active Record. Mapping Active Record objects to database table occurs automatically and can also be overwritten.
Active Records main contribution to object relational mapping is to solve the problem of inheritance and associations. active record(http://api.rubyonrails.org/classes/ActiveRecord/Base.html)
Features of Active Record
Mapping between Classes, Tables, Attributes and Columns
class Post < ActiveRecord::Base; end
maps to a table named posts which is defined in the database as:
CREATE TABLE posts
(
id int(11) NOT NULL auto_increment,
name varchar(20),
title varchar(30),
content varchar(255),
cheer integer,
PRIMARY KEY (id)
);
Creating an Active Record
An Active Record accepts constructor parameters either in Hash form or normal block. Hashes are generally used when we generally receive data from somewhere else like HTTP requests.
post = Post.new(:name => "ABC", :title => "Greeting", :content => “Hi, How are you?”, :cheer =>0)
A Block allocation can be any of the following forms:
post = Post.new do |p|
p.name = "ABC"
p.title = "Greeting"
p.content = “Hi, How are you?”
p.cheer=0
end
or we can also create a bare object and assign them values as follows
post = Post.new
post.name = "ABC"
post.title = "Greeting"
post.content = “Hi, How are you ?”
post.cheer = 0
Conditions
Conditions can also be specified as a string, array or hash in the ruby expression
Post.find(:all, :conditions => { :name => "ABC"})
The above statement finds all the posts WHERE name is “ABC”. The WHERE conditions are specified in the above format in Ruby.
Overwriting Default Accessories
Column values are available through basic accessories on the Active Record. Over writing the default accessories can be done by using either
read_attribute(attr_name)
write_attribute(attr_name, value)
The cheer attribute of the Post table can be read by using
read_attribute(:cheer)
and its value can be changed by using
write_attribute(:cheer, 1)
Dynamic attribute-based finders
Dynamic attribute-based finders is a way of getting objects without actually writing the SQL queries.
Post.find_by_name(“ABC”)
returns all the posts made with the name ABC. The dynamic attribute finder can also be used to create new record if it does not exist by
Post.find_or_create_by_name("AFC")
is equal to
Post.create(:name => "AFC")
Associations between objects
Associations between objects can be controlled by small meta programming definitions. They are used for tying objects together with foreign keys.
class Post < ActiveRecord::Base
has_many :comments
has_one :name
end
Cardinality and Associations
All the cardinality and associations of the relational database model can also be expressed in the Active Record.
- One to one -- is represented by has_one : name
- One to Many -- is represented by has_many : comments
- Many to Many -- many to many can be represented in two ways.
- First is using a has_many relation which a :through option and join model
class Post < ActiveRecord::Base
belongs_to :comments
end
class Comment < ActiveRecord::Base
has_many :posts, :through => :posts
end
- Second method is to use the has_and_belongs_to_many in both the classes
class Post < ActiveRecord::Base
has_and_belongs_to_many :comments
end
class Comment < ActiveRecord::Base
has_and_belongs_to_many :posts, :through => :posts
end
Aggregations
They can be done using small meta programming definitions. This uses a class method called composed_of for representing attributes as value objects.
class Customer < ActiveRecord::Base
composed_of :balance,
:class_name => "Money" :mapping => %w(balance amount),
composed_of :address, :mapping => [ %w(address_street street), %w(address_city city) ]
end
The above Aggregates Address with individual attributes like street and city. It also maps money as the balance amount left in the customer's account.
Validations
Validations inspect the sate of an object which means a number of attributes have a certain value(such as not empty, within a given range, matching a certain regular expression)
class User < ActiveRecord::Base
validates_presence_of :name
validates_uniqueness_of :name
attr_accessor :password_confirmation
validates_confirmation_of :password
validate :password_non_blank
end
The above database table user has a number of validations on its attributes. Like, validates_presence_of implies that the attribute or field name cannot be nil or empty and also it should be unique since we also used validates_uniqueness_of. The field password cannot be blank and also the password attribute should match with the password confirmation which is implied from validates_confirmation_of and password_non_blank.
Callbacks
Callbacks can be used to trigger methods before or after an alteration of the object state. An object state can be altered in many ways like deletion updating etc.
An example callback method could be
class Post < ActiveRecord::Base
def before_destroy
Comment.find(post_id).destroy
end
end
The above is a callback method called when a post is deleted. If a post is deleted all its corresponding comments should also be deleted. Hence we use a call back method to make sure that we remove all the respective comments from the database.
Several Other validate states could be
- save
- valid
- before_validation
- before_validation_on_create,validate
- validate_on_create
- after_validation
- after_validation_on_create
- before_save
- before_create
- create
- after_create
- after_save
Observers
Observers are generally used to trigger methods outside the original class. They have a similar behaviour to callbacks.
class Post < ActiveRecord::Observer
def after_create(post)
contact.logger.info('New post added!')
end
end
The above adds information about a class post which adds to the logger after every creation of a new entry in the post table. Notifications can also be set using the same procedure.
Inheritance
Active record allows inheritance by storing the name of a class in a column that by default is named type.
An example to inheritance would be
class User < ActiveRecord::Base; end
class Post < User; end
class Comment < Post; end
The above notation defines User being an inherited class from the default Active Record base class. Post is a subclass of User and Comment is a subclass of Post.
Other ORM's in RUBY
Data Mapper
Data mapper(http://datamapper.org/) is an Object Relational Mapper written in Ruby which is fast, thread-safe and feature rich. The advantages of Data Mapper over other ORM’s are
- Uses the same API to communicate with different datastores.
- Less Migrations
- DataMapper makes it easy to leverage native techniques for enforcing data integrity
- Everything is an object
- Custom Validation on object properties.
- Lazy Loading (related objects are only loaded upon access).
- Relations and their integrity are automatically managed for you.
- One to One, One to Many, and Many to Many relations fully supported.
SEQUEL
SEQEUL(http://sequel.rubyforge.org/documentation.html) is a Database toolkit for Ruby. Its ability to represent SQL queries themselves as objects is its major feature.
- Sequel is a simple, flexible, and powerful SQL database access toolkit for Ruby.
- Sequel provides thread safety, connection pooling and a concise DSL for constructing
- SQL queries and table schemas.
- Sequel includes a comprehensive ORM layer for mapping records to Ruby objects and handling associated records.
- Sequel supports advanced database features such as prepared statements, bound variables, stored procedures, savepoints, two-phase commit, transaction isolation, master/slave configurations, and database sharing.
- Sequel currently has adapters for ADO, Amalgalite, DataObjects, DB2, DBI, Firebird, Informix, JDBC, MySQL, Mysql2, ODBC, OpenBase, Oracle, PostgreSQL, SQLite3, and Swift.
References
- http://api.rubyonrails.org/classes/ActiveRecord/Base.html
- http://www.agiledata.org/essays/mappingObjects.html
- http://www.c2.com/cgi/wiki?ObjectRelationalMapping
- http://www.objectarchitects.de/ObjectArchitects/orpatterns/
- http://guides.rubyonrails.org/active_record_querying.html
- http://datamapper.org/
- http://www.service-architecture.com/object-relational-mapping/