CSC/ECE 517 Fall 2010/ch2 S20 TT
'Code Reuse'
Code reuse implies the capability of software to allow the practice of reusing a part or module of the code, which saves the programmer from re-building a new application from scratch. This prevents a lot of redundancy in coding for programmers and also the time and effort spent in writing code.
Granularity
For any article that comprises of large amount of information that needs to make enough sense for the user, it needs to be categorized in some or other way. There should be some unit of categorization to organize an article in an efficient manner. Similarly, for any complex software application to be understood and controlled well there should be a high level categorization implemented to achieve the purpose. For Example, consider an application for a store. There are different entities in the store, like cart, user, cashier, etc. If we implement an entity, say cart, using a single array, we cannot use attributes like iscartempty(), iscartavailable(), etc. for the cart. But, if we implement the entity as a class we can extend the usability of the class by implementing any function that makes sense.
Granularity is the level or the extent to which any system or a function can be subdivided into relatively smaller modules. For example, all the roads in U.S can be classified to rural and urban roads. All the rural roads can be further classified into arterials, collectors and local. All materials can be still classified into principal and minor and soon. The amount of classification is different to different classes of users.
For many Object Oriented Languages and Systems, the basic unit of categorization can be termed as package. Although Class might be a potential option for some cases, but for larger and complex applications it may not be a convenient way to categorize. For such cases a package can be used to represent data that can be imported into other applications. A package can contain a set of particular classes that are partitioned based on some criterion. For example, for a typical java application all the database classes can be grouped into one package and all the development classes can be grouped to one package. The application classes can import database classes.
Note: A package here is not used for referring java package. It is being used in much general sense.
But this partitioning of classes into a particular package is based on several factors like
1) Cohesion: Assigning a set of classes to a particular package.
2) Coupling: Designing the dependencies between different packages and their design principles.
3) Dependency: Denotes the package structure whether it is top-down or bottom-up.
Package Cohesion:
The following are a set of principles that are used to satiate the cohesion property of a package.
1) Reuse-Release Equivalence Principle
2) Common-Reuse Principle
3) Common-Closure Principle.
Reuse-Release Equivalence Principle (REP)
What is Reuse? The common conception about reuse is copying the code of one class into another class. But what actually happens when the code is changed by the source? Does it get reflected in the user code? Does a normal user can understand what exactly had happened and what got changed? For example, consider the following scenario. Initially the author dispatches a piece of code to a user for some application. At some point of time the author realized that there is a bug in the code that needs to be fixed. The author then changes the code to fix the bug. Since the user does not know the change that was done by the owner, he tries to modify the code to fix the bug. The user code will change gradually from the initial code. Finally, this doesn’t serve the point of re-usability.
The reuse of code by copy pasting in general is not a good idea and programmers should refrain from doing so. Instead Reusability can be achieved by using libraries. The author will create a library that consists of all his code that is needed by the user and sends it to the user. The user will simply include the library into his piece of code and can access all the information from the library. This way, the user makes changes to his code, not to the library, to satisfy his needs there by implying the convergence of the original code and the current code. So, if the author wants to change his code either for fixing bugs or renovating code to implement new functionality or to modify the existing functionality, he will change his code and will send it to the user as a new set of code (Versions are covered in the next section). The user will have no control over the source code of the library. Since, the user cannot control the code, it can be treated as an end product so that the customer( the user in this case) need not maintain it. So he can either accept the new code to reflect the changes in his current code and can avail of the new functionality or can reject it.
A special tracking system might be needed for the user to know whenever the author changes his code. Version number is useful to achieve this purpose. The new set of code is represented by the version number. Every time the author changes the code, he will release it as a new version. This practice helps users identify the version number they are handling with and correspondingly manage their code. If a user wants to use an earlier version of the code, he can get to know it by the version number.
When a bug is identified within a reused component, the exact version of the component can be identified with the use of this tracking system. “The Granule of Reuse is the Granule of Release”
This principle suggests that the reusability is to be done based on the granule of reuse, the package. It might be possible to use class as a granule for reuse but it would result in enormous number of classes which makes life miserable. A reusable package should consist of only reusable classes. This makes the whole unit a reusable unit so that the user can accept the version to avail of its functionality or can reject the version. So, either all the packages in the class are reusable or none of them. This avoids accidental reuse of non-reusable packages.
Even if the user accesses only one or two classes the whole granularity to be considered is the entire package. Example: Packaging in Eclipse JDT Core Plug-in

The Java packages org.eclipse.jdt.core.* contain the reusable parts of the JDT core. The Java packages org.eclipse.jdt.internal.* contain internal classes, i.e., classes that are not designed for reuse.
Common Reuse Principle (CRP)
The Reuse-Release Equivalency Principle sheds light on the importance of the package, its tracking mechanism and achievement of reusability. However, the main part of cohesion, i.e., the set of classes that can be bounded into a package has not been determined yet. If the classes that are bounded are not selected properly, then numerous dependencies that are not needed might turn up and the whole concept of packages will fail.
The Common Reuse Principle will help in identifying the set of classes that can be grouped into a particular package.
“The classes in a package are reused together. If you reuse one of the classes in a package, you reuse them all”
The principle states that only classes that are cohesive should be grouped together. This cohesiveness is based on the user’s perspective. Generally the classes that need to be reused will belong to the same package. For example, all the applet concepts are grouped into one package and all the swing concepts into another one.
Consider the scenario where two classes are not tightly bound in a package. The user wants to access only one particular class from the package. Every time a new version of the package release, the user has to re-validate the whole project even if the class that he is not interested in changes. This results in another reason where each and every class in a package must be tightly bound. So if every class in a package depends upon every other class in a package the user can re-validate to the newer version.
If a particular class is not tightly bound to another reusable class then those two classes must not be in the same package. This makes sure that each and every class in the package is bounded tight to each and every other process in the package. This eliminates the possibility of a class depending only on a particular class but not the other class.
1.jpg)
The Java package org.eclipse.jdt.core.formatter contains functionality to format source code.
The CodeFormatterApplication depends on messages.properties and CodeFormatter which in turn depends on DefaultCodeFormatterConstants.
Ispace DEMO violates Common Reuse Principle in edu.berkeley.guir.prefuse.event where numerous clients reuse only a small part of the event package.
Dependencies and Cycles
“The morning after syndrome” is a case where there would be multiple developers that are sharing the same resource and even if one develops an application that can run in all cases, there might be an interception from any other user who changes the code that it no longer works. Everyone will try to make their own code work and in the mean process they are altering others resources which leads to an inconsistent state.
Dependencies between different developers code is necessary but too much of dependencies results in this problem.
Dependency cycles are the cycles where both the packages, either directly or indirectly, depend on each other. These cycles make the situation even worse.
The solution to this problem can be achieved by using the following two approaches.
The weekly Build
This method is commonly used in medium sized projects. For the whole week, except the final day of the week, the developers will work on the classes independently and on the final day they will unite all the work they have done during the week. Advantages: It is relatively simple and sufficient for medium sized projects in most cases. Disadvantages: It works only for smaller project. If the project grows with time then this method is almost impossible to employ.
Acyclic Dependency Principle (ADP)
“The dependency structure between the packages must be a directed acyclic graph (DAG). That is, there must be no cycles in dependency structure.”
As the name indicates that if a dependency graph is drawn among the users of a system, it should never have a cycle.
GOAL:
The main idea of this principle is to divide the project into several individual packages. The packages are created in such a way that they are independent for different users. So the interference between developers can be avoided by releasing packages as own units which will not affect the users immediately. Incremental integration needs to be done later at certain point of time to satisfy dependency.
ADP:
The whole development environment is first partitioned into a set of releasable packages. These packages are initially provided as an input to a developer or a team. Once all the changes to be implemented are done by the developer he will name a valid version to the updated package and pass this version to the directory so that next member or team can use it. A developer, in the meantime or later, will work on his own private area after passing the latest version to the directory. Everyone else will use the released version. Other teams can decide if they want to work on the new version or not. If they want to, they will accept the version otherwise they may continue to use the older version. They can use any version at any point of time since each version is specified using a unique number. This approach seems to be very simple but for it to work the directory structure needs to be managed well.
Package Dependencies
A package can depend on any number of other packages. For example a class in a particular package may include the header file of a class in a different package. This can be represented by the following diagram.

The following diagram shows the typical application involving lots of packages which are dependent on each other. The dependency structure is being represented as a graph where each package is represented as a node and each dependency is shown by an edge. These edges are directional edges since they only show a unidirectional flow. No matter whatever the process you start with, you will not end with the same process. This indicates that the graph has no cycles and hence is a Directed Acyclic Graph(DAG).

This structure is very much useful in the following sense. 1) It is very easy to find out which package or a node is affected by changing any other package. For example, changing database only affects MyTasks. 2) It is very easy to test packages in isolation. For example, to test the package tasks or database they can be done independently. For package MyDialogs it needs to be linked only with windows. 3) When the developers of a particular team want to release an updated version, we can find out the packages that are affected by the release by following the dependency arrow backwards. For example, if the package MyDialogs has been changed MyTasks and MyApplication are going to be affected 4) At the time of releasing the whole system it will be done from bottom to top. For example, the windows package is compiled, tested and released first. It is followed by MessageWindow and Mydialogs which are then followed by Task, Taskwindow and DataBase. Mytask is next and finally Myapplication will get tested and released.
Now consider the effect of cycle in the present graph. Let us consider a new edge, that is, a new dependency from MyDialogs to MyApplication. This means that MyApplication depends on MyDialogs indirectly and MyDialogs depends on MyApplication directly. In the previous case, for the package MyTasks to be compiled and released it depends on Task, Database, and MyDialogs. But since MyDialogs is dependent on MyApplication for the current scenario which in turn depends on MessageWindow, TaskWindow and Windows, it depends on all other packages in the current system. So, any developer or a team who is working on any of the above packages will experience the previous problem “the morning after syndrome”. This is not the only problem. If we want to test any of the packages, say Database, we need to link every other package and then compile. Complete building for every package would end up in intolerable overhead.
So, our goal is to remove the cycles, if there are any, to eliminate “the morning after syndrome” problem. There are two possible solutions for this problem.
1) Dependency Inversion Principle: This is one possible way of removing a cycle from the acyclic graph. We can design an abstract class that contains its interface that MyDialogs needs. We put this class inside the MyDialogs and make the other class MyApplication inherit from the other class. This will break the dependency between MyDiaogs and Myapplication.
The initial dependency can be shown in the following diagram.
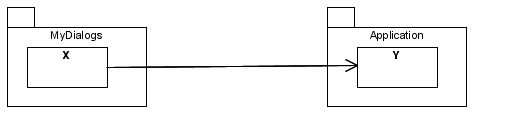

This would be changed by using Dependency Inversion Principle to the following dependency.

2) The other potential option is to create a new package that will consist of all the classes that are needed by both MyDialogs and MyApplication package. This will break the cyclic dependency since both the packages are no longer dependent on each other.
The direction of the dependency can be changed like this.
The second approach seems to be a simple way of breaking dependency cycles, but what exactly happens if we follow that approach? Normally, in a large project, there is greater probability for it to have large number of cycles. If we keep on breaking the dependency by creating new packages, we will end up with numerous numbers of packages.

Top-Down Design
A top-down strategy for a package hierarchy means that, if we consider a package at the top of the hierarchy, that project is assumed to be created first of all other projects in the hierarchy. But what actually happens in a dependency graph s that the package at some level will be developed only after many classes have been designed. For any application to start with, first we need to determine the functionality of the application. But package dependency will not make any sense in determining the functionality. The package dependency is a blue print of how to build the application. Initially, when determining the functionality of application, there won’t be any software to build. Hence there won’t be any use of package dependency rules. But once the software starts and it tries to accumulate more and more classes, we need to use this package dependency to build the project without “the morning after syndrome”. To build the packages that will have to bind a set of classes that are likely to change together we use Common Closure Principle. Common Reuse Principle will come into act when we start concerned about building reusable elements. This will determine the composition of packages. All these principles are needed to be followed in a specified order which, otherwise, will result in formation of cycles.
Code Reuse using Ruby on Rails:
Reusability is one of the main objectives of Ruby on Rails and the Don’t Repeat Yourself (DRY) principle in Ruby suggests that any definition should occur only once. Thus, the DRY principle promotes reusability and makes it easier to be used. Ruby provides two ways of reusing code namely the “concept of using methods” and the “concept of using modules”. The concept of reusing the methods relatively falls under the category of reusing small snippets of code that are encompassed in a method, which implies reusing code to a limited extent. Contrary to the concept of using methods, the concept of using modules involves reusing extensive code that is contained in a module.
The concept of using modules
Modules are defined as containers of one or more code snippets that might either be small or large depending on the requirements of the class. The code snippets can contain variables, class definitions not necessarily pertinent to the class defined in the snippet and also the methods.
The concept of reusing methods
Ruby provides a way to reuse code in the form of methods. Methods form the smallest unit of code to be reused. This is done using the proc object. Proc is an object in Ruby that contains a block of code. The block of code contained in the Proc object declares a set of local variables. When the proc object is called it will access the same variables that were bound to it during its initialization. In addition to the local variables, the proc object also contains a single method and the current state of the variable, which can be passed to methods utilizing the function calling method.
Ruby is a dynamically-typed language, which implies that the programmer needn’t explicitly define the type of a variable as in the case of other object-oriented languages such as Java or C++. Ruby will automatically try to figure out the type based on the usage of the variable. This is called as duck-typing in Ruby. It is called so, for the reason that any bird that behaves like a duck and quacks like a duck will be automatically called a duck, where in reality it needn’t actually be a duck. In Ruby, objects called are initialized dynamically by their behavior and not by their definitions unlike other object-oriented languages, which have their objects initialized before calling them later-on in the program. Thus, Ruby leads to a kind of polymorphism minus their dependence on inheritance.
The dynamism of Ruby is further fostered by the use of “mix-ins” in modules. Mix-ins come from the amalgamation of two words “mix” and “in”. Additional classes or functionality in existing classes can be added by mixing in newer methods. Thus, mixins prove a powerful tool than classes since defining functionality in a mixin means it can be called by any class that requires the functionality and not by the class alone where the functionality has been declared. Code from other modules too can be integrated within the module and called by declaring a statement that acts as if the module has been created at the time when the statement has been declared. Thus, previously defined modules can be implanted into the current modules to modify the active state of the module. Thus, the structure of the modules can change dynamically along the way of using the module based on the demands and requirements of the software. Modules can be integrated along with the inheritance concept of Object-oriented language systems to reuse the code in an efficient manner. The classes created within the modules can inherit from other classes. The beauty of Ruby lies with the fact that anybody can modify the previously defined classes in the libraries along the way. Apart from the feature to modify external classes by anybody, it also provides option to make a class read-only in order to restrict the permissions of usage of certain classes, thus promoting misuse of certain important classes.
Ruby plugins
A plugin is a piece of code that helps garner external help for developing application using Rails. The libraries are composed into structures called plugins for enhancing reuse of rails code. Application programmers can use pre-written libraries or compose their very own libraries to be reused later. Rails provide ample support for the use of plugins. There is an abundance of plugin support available from the open source community. Code reuse is furthered by the use of plugins for the reasons that the new plugins created in Rails are compatible with the older versions and thus, the newer parts injected conform to the current state of the application. Another advantage of using plugins includes the breaking up of code into small units. The small units exist on their own and hence, any modification or updating required to fix the code in the units can be done separately without altering the structure of the other units of code. Thus, rails code plugins improves the modularity of the code.
Plugins can be found using the following resources: 1) Technoweenie 2) Core Rails 3) Rails Wiki 4) Plugin Directory
Plugins can be used to do the following operations: Models : Plugins can be used to generate basic model of applications. Models are used to store information and manage the current state of the application. They are also used to notify the user of change in the state of the application immediately once the change occurs.
View Helpers: Views provide an interface to the users of the information stored in models. Thus, it provides the interactive medium required by users to communicate with the applications. Plugins can be used to design a user-interface for the applications. Views can be created using responses and layout structuring. Response corresponds to the action taken when the input is passed on to the controller. Layout is the response form that acts as the view for the output.
Controllers: Controller acts as the point of control. When the input is issued, the controller reacts to the input by instructing the model to perform the requested operations. The plugins can be used to implement a controller to handle models and views of an application.
Rake Tasks: Rake tasks are used to store the session data in its correct format in the database. Rake tasks are used to automate the tasks, which promotes reuse of code. The rake tasks themselves can be generated using plugins. Images, Stylesheets, Javascripts Plugins can be used to generate images, stylesheets and javascripts by using a generator and copying the files into the public directory.
Conclusion
A Package can be used as a basic unit of a project. The Composition of packages, like what types of classes can be embedded in a package, which classes to include and which are not to etc., is very important to avoid the cyclic dependencies which in turn reduce the complexity of the project. Robustness, Reusability and Maintainability can be achieved by using the three rules that were specified above. Cycles can be removed from the graph by using Dependency Inversion Principle that was specified above. The approach in designing a package should properly be taken into account, which otherwise results in “the morning after syndrome”. Cohesion and Coupling are the most important factors in deciding the dependency of packages among each other.
References
[1] Michael Bachle and Paul Kirchberg, “Ruby on Rails”, IEEE Software, 24(6), Pages105–108, 2007.
[2] Stuart Ellis, “The Key Ideas of the Ruby Programming Language”, “2010, Creative Commons Attribution-Share Alike 3.0 , 2010, License”, http://www.stuartellis.eu/articles/ruby-language. [3] Michael Morin, “Mixin Modules”, About.com:Ruby, http://ruby.about.com/od/beginningruby/a/mixin.html.
[4] J. D. An, A. Chaudhuri, and J. S. Foster. Static Typing for Ruby on Rails, In Proceedings of the 24th IEEE/ACM International Conference on Automated Software Engineering, Auckland, New Zealand, Nov. 2009.
[5] Lars Klevan, “Does Ruby on Rails Work For Larger Engineering Teams?”, Socialcast blog, August 2010, http://blog.socialcast.com/does-ruby-on-rails-work-for-larger-engineering-teams.
[6] Geoffrey Grosenbach, “The complete guide to Rails plugins: Part 1”, "nubyonrails.com", May 2006, http://nubyonrails.com/articles/the-complete-guide-to-rails-plugins-part-i.
[7] Benjamin Curtis, “Agile web-development”, 2010, http://agilewebdevelopment.com.
[8] Jaime Iniesta, “RailsGuide”, April 4, 2010, http://guides.rubyonrails.org/plugins.html.
External Links
[1] Granularity - http://www.objectmentor.com/resources/articles/granularity.pdf
[2] Reuse Maturity Model - http://www.anthillpro.com/html/resources/reuse-maturity-model.html
[3] Measurements and Metric - http://web.cs.wpi.edu/~gpollice/Maps/CS4233/Week5/CS4233%20Lecture%2015/index.html
[4] Principles of reuse - - http://stackoverflow.com/questions/63142/the-reuse-release-equivalence-principle-rep - http://c2.com/cgi/wiki?ReuseReleaseEquivalencePrinciple - http://ifacethoughts.net/2006/04/05/common-reuse-principle/ - http://www.st.informatik.tu-darmstadt.de/pages/lectures/se/ws06-07/design/lecture/10_principlesOfPackageDesign.pdf