CSC/ECE 517 Spring 2014/ch1a 1w1e rm: Difference between revisions
No edit summary |
|||
| Line 9: | Line 9: | ||
Before a coder performs a refactor, they must, either formally or informally, identify their ‘code smells’. A code smell refers to a negative quality of a code base that either implements bad programming practices or slows down code development or runtime. These aren’t typically bugs, but can increase the chance of bugs later on if not fixed. Based off of the type of code smell, a different refactoring technique is used to fix it. | Before a coder performs a refactor, they must, either formally or informally, identify their ‘code smells’. A code smell refers to a negative quality of a code base that either implements bad programming practices or slows down code development or runtime. These aren’t typically bugs, but can increase the chance of bugs later on if not fixed. Based off of the type of code smell, a different refactoring technique is used to fix it. | ||
==Duplicate Code== | |||
Duplicate code can be a tricky concept when refactoring. Large sections of duplicated code can be easy to find and fixed by pulling it out and creating a single centralized method to call, however it is usually not that easy. Sometimes it may only be one or two lines of code that are duplicated which calls for an assessment of whether or not it is in the best interest to create a new method for a couple lines of code. Other times, code is not duplicate, rather it is similar enough that a generic method could be created to serve various purposes. | Duplicate code can be a tricky concept when refactoring. Large sections of duplicated code can be easy to find and fixed by pulling it out and creating a single centralized method to call, however it is usually not that easy. Sometimes it may only be one or two lines of code that are duplicated which calls for an assessment of whether or not it is in the best interest to create a new method for a couple lines of code. Other times, code is not duplicate, rather it is similar enough that a generic method could be created to serve various purposes. | ||
Some specific techniques to deal with this are: | Some specific techniques to deal with this are: | ||
====Extract Method / Pull-up Method==== | ====Extract Method / Pull-up Method==== | ||
If common code is used in multiple places, simply pull it out and make a method that can be called from all of the necessary places. Variables can be passed in if slight variations are needed between calls. | If common code is used in multiple places, simply pull it out and make a method that can be called from all of the necessary places. Variables can be passed in if slight variations are needed between calls. | ||
If the code is used in various subclasses, put the common code in a method in the superclass, so that it can be seen and called by it’s children. | If the code is used in various subclasses, put the common code in a method in the superclass, so that it can be seen and called by it’s children. | ||
[http://www.refactoring.com/catalog/extractMethod.html Extract Method Example] | |||
===Form Template Method=== | |||
If two methods in subclasses perform similar steps in the same order, but the steps are different, then get the steps into methods with the same signature, so that the original methods become the same. Then pull them up. [http://www.refactoring.com/catalog/formTemplateMethod.html] | |||
[http://www.integralist.co.uk/posts/refactoring-techniques/#form-template-method Form Template Method Example] | |||
=== | ===Large Method/Class=== | ||
If a project is not planned out well enough in advance, it is easy for methods and classes to become populated with excess functionality. While the functionality may be necessary for the project, it might not be in the method or class. | |||
====Extract Method==== | |||
This can be used when duplicate code occurs, as discussed above. But it can also be used when a method performs multiple functions that have the ability to be split up into various functions that serve a single purpose. | |||
====Extract Class/Subclass/Superclass==== | |||
*If there are class variables or methods that don’t directly pertain to a class, then it may be necessary to create a new class for those pieces. | |||
[http://www.refactoring.com/catalog/extractClass.html Extract Class Example] | |||
*If there are pieces of a class that are only for a specific subset of instances, then a subclass can be constructed to contain these. | |||
[http://www.refactoring.com/catalog/extractSubclass.html Extract Subclass Example] | |||
*If there are pieces that multiple classes use, then a superclass can be constructed to handle these generic functions, leaving the subclasses to deal with the remaining differences. | |||
[http://www.refactoring.com/catalog/extractSuperclass.html Extract Superclass Example] | |||
===Improving Readability and Clarity=== | |||
A lot of times, refactoring can be used to do simple, yet necessary changes like renaming variables, methods, or classes. As features get added to a project, classes tend to get charged with more uses than originally planned, so sometimes, the original naming scheme no longer applies and a new one needs to be instilled. | |||
Moving methods and parameters around to where they have the best accessibility also has its uses. Classes also tend to be promoted or demoted to super and sub classes after their ultimate functional purpose is determined. | |||
====More Techniques==== | |||
There is an extensive list of coding smells that can are able to be improved through refactoring. | |||
A description of smells with their techniques exists [http://ghendry.net/refactor.html here]. | |||
A list of techniques with examples in Ruby are listed [http://www.refactoring.com/catalog/index.html here]. | |||
==Getting Started with Refactoring in Ruby== | ==Getting Started with Refactoring in Ruby== | ||
Revision as of 07:04, 10 February 2014
This page discusses how to elegantly refactor code, including several common metrics used in determining the potential quality of refactoring code, as well as which refactoring techniques to use in coordination with such metrics.
Background
The practice of code refactoring deals with changing the content or structure of code without changing the code's function in its execution. Code refactoring has become a standard programming practice, as it potentially promotes readability, extensibility, and reusability of code.
Whether done through an IDE or by hand, large-scale code projects can prove tedious to refactor. If minimal non-functional benefits are achieved through refactoring, time is wasted. Furthermore, if not done properly, code refactoring can actually break the functionality of the code. In the extreme case, code could be structured so badly that starting over completely may be more viable than refactoring. As such, it is important to be able to know when and what to refactor.
Refactoring Techniques
Before a coder performs a refactor, they must, either formally or informally, identify their ‘code smells’. A code smell refers to a negative quality of a code base that either implements bad programming practices or slows down code development or runtime. These aren’t typically bugs, but can increase the chance of bugs later on if not fixed. Based off of the type of code smell, a different refactoring technique is used to fix it.
Duplicate Code
Duplicate code can be a tricky concept when refactoring. Large sections of duplicated code can be easy to find and fixed by pulling it out and creating a single centralized method to call, however it is usually not that easy. Sometimes it may only be one or two lines of code that are duplicated which calls for an assessment of whether or not it is in the best interest to create a new method for a couple lines of code. Other times, code is not duplicate, rather it is similar enough that a generic method could be created to serve various purposes. Some specific techniques to deal with this are:
Extract Method / Pull-up Method
If common code is used in multiple places, simply pull it out and make a method that can be called from all of the necessary places. Variables can be passed in if slight variations are needed between calls.
If the code is used in various subclasses, put the common code in a method in the superclass, so that it can be seen and called by it’s children.
Form Template Method
If two methods in subclasses perform similar steps in the same order, but the steps are different, then get the steps into methods with the same signature, so that the original methods become the same. Then pull them up. [1]
Large Method/Class
If a project is not planned out well enough in advance, it is easy for methods and classes to become populated with excess functionality. While the functionality may be necessary for the project, it might not be in the method or class.
Extract Method
This can be used when duplicate code occurs, as discussed above. But it can also be used when a method performs multiple functions that have the ability to be split up into various functions that serve a single purpose.
Extract Class/Subclass/Superclass
- If there are class variables or methods that don’t directly pertain to a class, then it may be necessary to create a new class for those pieces.
- If there are pieces of a class that are only for a specific subset of instances, then a subclass can be constructed to contain these.
- If there are pieces that multiple classes use, then a superclass can be constructed to handle these generic functions, leaving the subclasses to deal with the remaining differences.
Improving Readability and Clarity
A lot of times, refactoring can be used to do simple, yet necessary changes like renaming variables, methods, or classes. As features get added to a project, classes tend to get charged with more uses than originally planned, so sometimes, the original naming scheme no longer applies and a new one needs to be instilled.
Moving methods and parameters around to where they have the best accessibility also has its uses. Classes also tend to be promoted or demoted to super and sub classes after their ultimate functional purpose is determined.
More Techniques
There is an extensive list of coding smells that can are able to be improved through refactoring. A description of smells with their techniques exists here. A list of techniques with examples in Ruby are listed here.
Getting Started with Refactoring in Ruby
The first step in refactoring is writing solid set of tests for that section of code to avoid introducing bugs. In Ruby, this can be done using Test::Unit or Rspec. Next step is to make small changes, test again, make small changes and so on. <ref>http://www.amazon.com/Refactoring-Edition-Addison-Wesley-Professional-Series/dp/0321984137</ref>
To start refactoring in Ruby, a CodeClimate blog suggests 7 patterns to refactor fat models in Ruby:
- Extract Value Objects
- Extract Service Objects
- Extract Form Objects
- Extract Query Objects
- Introduce View Objects
- Extract Policy Objects
- Extract Decorators
It is always confusing when to start refactoring. If either one of the following conditions is true, it is a good time to start refactoring code:
- The Rule of Three
- When you add function
- When you need to fix a bug
- During code review,
- For greater understanding
A CodeClimate blog also suggests some other conditions to identify the need to refactor code.
Metrics
There are a variety of metrics that are used to quantify the merits of refactoring. Nearly all of these metrics can be calculated by program analysis tools. The final metric mentioned could be calculated by some version control system.
Complexity
In general, complexity is a measure of the number of branches and paths in the code.
Cyclomatic complexity, in particular, is a popular metric for measuring a method's complexity. In its simplest form, cyclomatic complexity can be thought of as adding 1 to the number of decision points within the code <ref> http://www.codeproject.com/Articles/13212/Code-Metrics-Code-Smells-and-Refactoring-in-Practi</ref>. These include cases in switch statements, loops, and if-else statements. In the following example, there are two decision points (the if and the else), so the cyclomatic complexity is 2+1=3.
public void evaluate(condition) {
if(condition a) {
//do something
}
else {
//do something else
}
}
Cyclomatic complexity values are divided into tiers of risk, where values less than 11 are of low risk, values between 11 and 21 are of moderate risk, values between 21 and 51 are of high risk, and values greater than 50 are of extreme risk <ref>http://www.klocwork.com/products/documentation/current/McCabe_Cyclomatic_Complexity</ref>. For a method in the first tier (e.g. with a cyclomatic complexity of 10), refactoring may not be necessary. Conversely, for a method in the extreme risk tier (e.g. with a cyclomatic complexity of 2,000), throwing out the code and starting over may be the appropriate solution instead of refactoring. For a method with a cyclomatic complexity in one of the middle tiers, refactoring is likely the best option. The example below shows how refactoring can reduce the cyclomatic complexity of a method.
public void evaluateAll() {
for(int n = 0; n < conditionList.size(); n ++) {
if(conditionList.get(n).equals(a)) {
//do something
}
else {
//do something else
}
}
}
Using extract method on this simple example, the original method can be reduced to the following two methods.
public void evaluateAll() {
for(int n = 0; n < conditionList.size(); n ++) {
evaluate(conditionList.get(n));
}
}
public void evaluate(condition c) {
if(c.equals(a)) {
//do something
}
else {
//do something else
}
}
In this manner, the cyclomatic complexity of the original method is reduced. Intuitively, choosing code with higher cyclomatic complexity yields a better-quality refactoring.
Duplicate Code
The metric of duplicate code is the number of times similar code structures are detected in a program. For example, although they are used to print different statements, the following code fragments contain similar structures.
System.out.println("Player position: " + player.position[0] + " " + player.position[1] + " " + player.position[2]);
System.out.println("Enemy velocity: " + enemy.velocity[0] + " " + enemy.velocity[1] + " " + enemy.velocity[2]);
If they were unified into a single method, both reusability and extensibility of the code's function would be improved. Once again using the extract method operation (or extract class, depending on the context), a new method can be created to facilitate the function of both previous code fragments. This is shown below.
public void printAttribute(String description, float attribute[]) {
System.out.println(description + ": " + attribute[0] + " " + attribute[1] + " " + attribute[2]);
}
Using this unified method in the respective locations of the original code fragments allows function to remain unchanged.
printAttribute("Player position", player.position);
printAttribute("Enemy velocity", enemy.velocity);
The extract method solution to refactoring code is not the only example of how to refactor duplicate code structures. For example, within a single class, the printAttribute method might might solve local duplication issues, but issues could still exist outside of the class. For example, such a method could be defined in two related classes, as shown below.
class Enemy extends MovingObject {
// ...non-duplicate variables for Enemy class
// ...non-duplicate methods for Enemy class
public void printAttribute(String description, float attribute[]) {
System.out.println(description + ": " + attribute[0] + " " + attribute[1] + " " + attribute[2]);
}
}
class Player extends MovingObject {
// ...non-duplicate variables for Player class
// ...non-duplicate methods for Player class
public void printAttribute(String description, float attribute[]) {
System.out.println(description + ": " + attribute[0] + " " + attribute[1] + " " + attribute[2]);
}
}
In the case of these two classes, printAttribute is shared by both. Assuming all subclasses of MovingObject contain some float array of size three, implementing the pull-up method refactoring pattern would move the printAttribute into the MovingObject class. Thus, the duplication issue would be resolved.
In practice, no code structure should exist in more than one location <ref>http://sourcemaking.com/refactoring/duplicated-code</ref>. As such, addressing code with the most duplicate structures yields the highest quality of refactoring.
Method and Class Length
The length of both methods and classes is also used as a metric to determine the potential quality of refactoring. Unlike the previous two metrics, however, the length of a method or class does not directly imply a problem in code design. Rather, the greater length that a method or class has likely implies that there may be another issue that can be quantified in other metrics (such as high complexity and duplicate code)<ref>http://blog.codeclimate.com/blog/2013/08/07/deciphering-ruby-code-metrics/</ref>. Method and Class lengths are not only calculated through the number of non-commented lines of code within each, but also through the number of members, parameters, variables, and imports <ref>http://trijug.org/downloads/refactor-metrics.pdf</ref>.
In practice, classes with more than 1,000 lines of code and methods with more than 100 lines of code should be refactored.
Volatility
The metric of volatility is a measure of the number of changes in code over time <ref>http://www.grahambrooks.com/blog/metrics-based-refactoring-for-cleaner-code/ </ref>. Although by itself, volatility is not a very useful metric to use in refactoring, it attains such merit when plotted against complexity. The relationship between volatility and complexity is shown in the table below.
| Low Volatility | High Volatility | |
|---|---|---|
| High Complexity | Low Priority | High Priority |
| Low Complexity | No Priority | No Priority |
As shown in the table, code with a low volatility and low complexity does not need to be refactored. The same is true for code with a high volatility and low complexity, as there is little potential for future problems in the code. In regards to code with a high complexity but low volatility, refactoring should occur, but it is not of the highest priority. Code that has both a high volatility and high complexity, however, is assigned the highest priority.
Review of Metrics in Practice
In review, the question of when and what to refactor can be determined by prioritizing refactoring based upon the highest potential quality to be gained through the refactoring. In regards to the metrics presented above, the priority of refactoring code should increase when:
- Methods in the code have a high cyclomatic complexity.
- There exist multiple duplicate code structures.
- Methods have more than 100 lines of code.
- Classes have more than 1000 lines of code.
- The code possesses a high cyclomatic complexity and volatility over time.
Automated Code Refactoring
- RubyMine
- RubyMine has a built in refactoring menu.
- Select a symbol or code fragment to refactor. Refactorings available for your selection appears. <ref>http://www.jetbrains.com/ruby/webhelp/refactoring-source-code.html#common</ref>
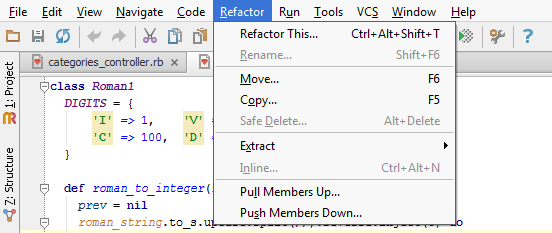

- RFactor
- RFactor is a Ruby gem, which aims to provide common and simple refactorings for Ruby code for text editors like TextMate
- The first release has only Extract method implemented while other refactorings are coming soon
- It is available on GitHub
- Some other IDEs with built-in refactoring include Aptana Studio, Aptana RadRails and NetBeans 7 (which requires Ruby and Rails plugin).
- A StackOverflow post compares these tools ranking them as RubyMine being the best followed by NetBeans, RadRails 2 and Aptana Studio 3
Further Reading
References
<references/>