CSC/ECE 517 Fall 2013/ch1 1w10 ga: Difference between revisions
(→Chef) |
(→Chef) |
||
| Line 220: | Line 220: | ||
</li> | </li> | ||
<li>This file is then uploaded to the chef server using following command:</li> | <li>This file is then uploaded to the chef server using following command:</li> | ||
knife role from file roles/redis.rb</li> | knife role from file roles/redis.rb</li> | ||
<li>Role is assigned to the server during bootstrap(explained in next section) using command : | <li>Role is assigned to the server during bootstrap(explained in next section) using command : | ||
knife ec2 server create</li> | knife ec2 server create</li> | ||
</ol> | </ol> | ||
Revision as of 01:11, 17 September 2013
Introduction
Infrastructure Managment Tools are becoming more widely used today and it is a skill set that is growing rapidly in development. With systems growing in size and complexity automated tools are becoming the norm as opposed to the exception.
Here we shall compare two popular Infrastructure Management Tools-
- Puppet
- Chef
We shall begin with an initial overview of both tools to familiarize the reader. We will then take a hypothetical scenarion and try and solve the problems in those scenario using Puppet and Chef.
We will then compare the solutions and compare how each tool handles the same problem. We do not intend to categorically state the superiority or suitability of one tool over the other but to illustrate their usage and let the reader choose them as per her/his need.
Overview of Puppet
Puppet is a Infrastructure Management tool written in Ruby. It's primary use is to manage the setup and configurations of machines or instances. For this reason it is widely used by system administrators and DevOps personnel to setup and maintain systems.
Puppet works in two fundamental modes -
Serverless Puppet
In Serverless Puppet each instance with Puppet installed is standalone i.e is independent and running without external supervision.
Effectively there are two processes-
- A master process
- An agent process
The master process consumes the configuration requirements fed it via Puppet and the agent applies it. Here the particular instance running Puppet has complete access to it's own configuration information.
Master / Agent Puppet
This is a typical client server pattern.
Here there is a central Master Puppet instance. This master instance contains the configuration information for all the Agent Puppet instances.
The Agent puppets are configured to periodically inform the Master with “Facts” which is basically information about the current state of the Puppet configuration.
The Master Puppet compares the state of each Agent with what it actually should be and sends it a “Catalog” which tells the Agent how it should configure itself.
After the Agent receives the Catalog and does the required changes it Reports back to the Master informing it of the status of the changes.
A point here to note is that no Agent can see the configuration information of other Agents except it's own which it receives via the Catalog from the Master
INSERT DIAGRAM
Resources
Up till now we have been discussing the “configuration” a machine in abstract terms. This is where one of the key features of Puppet comes up.
Puppet treats the configuration of each machine as being made up of atomic units called Resources.
A resource can be -
- A file that needs to present at a particular location, with particular permissions, having some content etc
- A package that needs to be installed
- A service that needs to be running
and so on.
Puppet has a declarative DSL wherein a resource can be described which is in the following format-
resource_type { 'resource_tile':
attribute_1 => value_1,
attribute_2 => value_2,
…..
}
An example would be -
service { 'rails s':
ensure => 'running'
}
We would include this resource as part of our Rails server configuration to ensure that our server is always running.
The attributes vary depending on the type of the resource and the values belong to range depending on the attribute and the resource type.
A very key feature to be noted here that Puppet focuses on the WHAT instead of the HOW.
What does this mean? Let us take the above example – the command to start a process would be different depending on the OS. But Puppet abstracts that complexity for us – we need only tell it HOW we want the machine to be i.e we want a particular process running and Puppet handles the rest – we tell it the state we want it to be and Puppet makes it so.
Overview of Chef
Opscode Chef is an infrastructure automation and configuration management framework.
Chef is used for configuration, deployment and scalability of servers and applications for eg: it can be used to deploy and manage network in cloud, on-site or a hybrid one with n number of servers. This helps organization to save time, solve mission-critical challenges, accelerate time to market, manage scale and complexity, and safeguard systems.
Chef client works using the abstraction definitions know as cookbooks and recipes that are written in Ruby. Chef client uses this definitions to build and manage servers in an infrastructure.
Elements
Basically an organization consists of following elements with chef configuration:
- Node : Any physical, virtual server is referred to as node.
- Knife : An interface between the local chef-repo and the server is known as knife. It is a command line tool using which users can manage other elements of the setup.
- Workstation : It is a computer used to interact with the single server. It is also used by users to run the knife command.
- Repository : usually referred as chef repo is the location wher all data objects are stored like cookbooks, configuration files etc.
- Hoster server: The stores manages cookbooks and all the configuration details that need to be applied to nodes.
- Chef-client : Chef client acts as an interface between the node and hosted server. Node gets all the configuration details from server via the client.
- Cookbook : Cookbook stores the configuration details depending upon the scenario for eg: in order to install Apache Tomcat server it contains details about installation, upgradation, components needed to support the server.
The Scenario
The scenario we will be using for the purposes of this comparison will be one that is a very prevalent one - a large scale web application infrastructure. We shall assume that the web application under discussion is being developed used Rails though this does not overly affect the infrastructure management - it is equally applicable to other frameworks.
The specific requirements of this sample project are as follows-
- Zero downtime - the website's operation is a critical part of the client's business model. They require that the website should have zero downtime which means the infrastrucutre must handle failures, deployment and maintenance without interrupting the site's operation.
- Large scale - The client anticipates a very high and dynamic load on the site which means the site should adapt to user demand and the infrastructure should be able to handle the required performance.
- System Integration - The project is being built to be integrated with the client's legacy systems and need to integrate with them. The infrastructure must support the connection between these systems.
Tasks: Use Cases
To achieve the above goals various tasks need to be accomplished. We shall look at each of these tasks in turn and see how they can be accomplished using Puppet and Chef and compare them in each use case.
Installation and Setup
As part of our example scenario we shall assume that our environment consists of a collection of Amazon Web Services (AWS) instances.
Puppet
Puppet can be installed via packages for debian and yum based systems. The package source need only be configured the normal way and the package to be installed.
A particular instance needs to be chosen as the Puppet Master and the puppet-server package needs to be installed on it.
The remaining instances need to have the puppet package installed on it.
Once that is the Puppet Master needs to be configured with a valid host name. Then the agent nodes need to be configured to point to the host name of the server.
Finally the Puppet Master needs to sign of on the certificate of each Puppet Agent that will communicate with it as all the communication between the Puppet nodes is encrypted and the services of the master and agent nodes need to be started
Chef
- Install chef server on the server machine
- Setup workstation:
- Pre-requisites : The workstation must have a Virtual box , vagrant(command line interface tool), Git( needed for Version Control Systems)
- Use knife client command to establish an API client identity for the workstation in order to make authenticated requests to the server. Setup chef-repo in the workstation.
- Create Cookbooks:
- In order to use community cookbooks one can just run the following command:
- Note: Chef has maintained a list of community cookbooks which are commonly covered under the use cases like apache2, mysql,php. So a user can leverage the community cookbooks instead of creating their own cookbooks.
- In order to create our own cookbook:
- The file default.rb in the path chef-repo/cookbooks/aliases/recipes/default.rb can be edited in order to create recipes.
- To make these cookbooks available to the nodes, it is first uploaded in the chef server.
- Setup chef client: Using knife tool in workstation, chef clients are setup on nodes.
How They Compare
Similarities
- Separate packages need to be installed for the client/agent and server/master for Chef and Puppet respectively
- Both use SSL encryption to communicate
Differences
- Puppet uses hostnames to uniquely identify whereas Chef uses Fully Qualified Domain Names
- With Puppet each individual node has to be accessed for the installation.However with Chef installation of an agent node can be done remotely
- With Chef a chef-repo needs to be installed on a workstation to use various Chef tools but with Puppet the puppet package is sufficient
Configure a Node
Our sample project will be using MongoDB. So the next task will be setting up the MongoDB instances.
Puppet
As we have seen in Puppet a machine’s configuration is specified in terms of resources. To tell Puppet to set up those resources on a machine we use a Manifest that consists of various resources.
But setting up a Manifest that covers all the Resources will quickly become unwieldly.
Which is why Puppet uses Classes and Modules.
A Class is a named collection of resources. A Module encloses a Class and is something that can be included in other Puppet files thus enabling reuse. There is a large collection of Modules called the Puppet Forge that has been written covering different type of uses.
Thus setting up a manifest for a MongoDB server is as simple as-
class { ‘mongodb’ :
init => ‘sysv’,
version => ‘1.1.1’ # installing a specific version of mongodb
}
include mongodb
# custom puppet code as per our requirments
Thus different Classes can be written which use different Modules for different uses. We can define a different class for our web server , for our file share and so on.
Once a Class has been defined by us that is tailor made to our uses setting up more instances is simply a question of provisioning the node and running the Puppet class on it.
This supports quick and simple scaling up.
Chef
Configuration in Chef is done by defining Role. Role helps in setting required attributes and tasks for a node. A node can have 0 or more roles assigned to it. Also a role can be assigned to many nodes. Roles thus helps in defining processes for a particular node.
Let us consider to configure a role for mongoDb server for a application:
- A role can be created by creating a file under roles directory for eg : roles/role_file.rb
- This file is composed of
- name : defines the node.
- description: describes about the node.
- attributes: attributes specific to the node which needs to be configured.
- run lists: tasks assigned to the node.
- Sample-
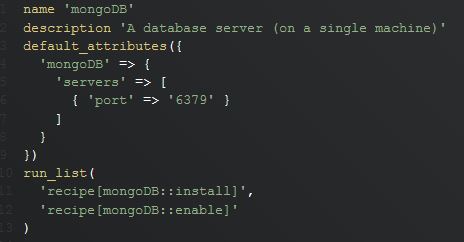
- This file is then uploaded to the chef server using following command: knife role from file roles/redis.rb
- Role is assigned to the server during bootstrap(explained in next section) using command : knife ec2 server create

How They Compare
Setting Up A Node
Puppet
In Puppet once we have identified what will go into defining something that we will need an instance for - as we have seen above say configuring a MongoDB instance - we need to select a fresh instance and apply the manifest to it.
As we have seen Puppet Agents will automatically sync with the Puppet Master. So the only task left for us is to
- Provision a new instance
- Install Puppet on it
- Classify it as a particular type of node.
The last two commands can be combined using the puppet init command-
puppet node init \ --node-group=db \ …. ( login related options) ec2-71-73-79-83.compute-1.amazonaws.com
Here we have specified the fresh instance and initialized as belonging to the group of nodes as db.
Once this process is done the instance will be classified as a db instance and will automatically begin syncing with the Puppet Master.
Chef
How They Compare
Node Management
Foreman
Foreman is a popular tool that is used in conjunction with Puppet. It provides a Web based GUI that lets users manage Puppet nodes.
As an example the following screenshot illustrates how Foreman can be used to manage multiple nodes across multiple environments-

We can apply various filters here to narrow down on a particular instance or conversely modify multiple nodes at the same time.
Knife
How They Compare
Config Files Deployment
Puppet
In Puppet files are treated as resources. So we could specify for an NFS node as follows-
file {'mount_conf':
path => '/etc/exports',
ensure => present,
mode => 0777,
content => "/some/path 192.168.100.1(rw,sync)”,
}
However the content would be different for different nodes as the environment would change.
Instead of creating a different resource for each template Puppet supports templatization of config files using Embedded Ruby (ERB).
We can re-write the same resource as follows-
file {'mount_conf':
path => '/etc/exports',
ensure => present,
mode => 0777,
content => template(“nfs/mount_conf.erb”),
}
where the mount_conf.erb file would contain Embedded Ruby code along with the appropriate Ruby variables which would automatically be compiled to give the right values to produce the conf file.
We can apply this same manifest file to all nodes across all the instances.