|
|
| Line 1: |
Line 1: |
| Supplement to Chapter 3: Support for parallel-programming models. Discuss how DOACROSS, DOPIPE, DOALL, etc. are implemented in packages such as Posix threads, Intel Thread Building Blocks, OpenMP 2.0 and 3.0.
| |
|
| |
| ==Overview== | | ==Overview== |
| | The main goal of this wiki is to explore synchronization mechanisms in various architectures. These mechanisms are used to maintain program “correctness” and prevent data corruption when parallelism is employed by a system. This wiki will first give a brief description of various parallel programming models that could be using the synchronization mechanisms, which will be covered later in the wiki. |
|
| |
|
| In this wiki supplement, we will discuss how the three kinds of parallelisms, i.e. DOALL, DOACROSS and DOPIPE implemented in the threads packages - OpenMP, Intel Threading Building Block, POSIX Threads. We discuss each package from the perspective of variable scopes & Reduction/DOALL/DOACROSS/DOPIPE implementations.
| |
|
| |
| ==Implementation==
| |
|
| |
| ===OpenMP===
| |
| The OpenMP Application Program Interface (API) supports multi-platform shared-memory parallel programming in C/C++ and Fortran on all architectures, including Unix platforms and Windows NT platforms. Jointly defined by a group of major computer hardware and software vendors, OpenMP is a portable, scalable model that gives shared-memory parallel programmers a simple and flexible interface for developing parallel applications for platforms ranging from the desktop to the supercomputer.
| |
|
| |
| ====Variable Clauses ====
| |
| There are many different types of clauses in OpenMP and each of them has various characteristics. Here we introduce data sharing attribute clauses, Synchronization clauses, Scheduling clauses, Initialization and Reduction.
| |
| =====Data sharing attribute clauses=====
| |
| * ''shared'': the data within a parallel region is shared, which means visible and accessible by all threads simultaneously. By default, all variables in the work sharing region are shared except the loop iteration counter.
| |
| Format: shared ''(list)''
| |
|
| |
| SHARED variables behave as follows:
| |
| 1. Existing in only one memory location and all threads can read or write to that address
| |
|
| |
| * ''private'': the data within a parallel region is private to each thread, which means each thread will have a local copy and use it as a temporary variable. A private variable is not initialized and the value is not maintained for use outside the parallel region. By default, the loop iteration counters in the OpenMP loop constructs are private.
| |
| Format: private ''(list)''
| |
|
| |
| PRIVATE variables behave as follows:
| |
| 1. A new object of the same type is declared once for each thread in the team
| |
| 2. All references to the original object are replaced with references to the new object
| |
| 3. Variables declared PRIVATE should be assumed to be uninitialized for each thread
| |
|
| |
| * ''default'': allows the programmer to state that the default data scoping within a parallel region will be either ''shared'', or ''none'' for C/C++, or ''shared'', ''firstprivate'', ''private'', or ''none'' for Fortran. The ''none'' option forces the programmer to declare each variable in the parallel region using the data sharing attribute clauses.
| |
| Format: default (shared | none)
| |
|
| |
| DEFAULT variables behave as follows:
| |
| 1. Specific variables can be exempted from the default using the PRIVATE, SHARED, FIRSTPRIVATE, LASTPRIVATE, and REDUCTION clauses.
| |
| 2. Using NONE as a default requires that the programmer explicitly scope all variables.
| |
|
| |
| =====Synchronization clauses=====
| |
| * ''critical section'': the enclosed code block will be executed by only one thread at a time, and not simultaneously executed by multiple threads. It is often used to protect shared data from race conditions.
| |
| Format: #pragma omp critical ''[ name ] newline''
| |
| ''structured_block''
| |
|
| |
| CRITICAL SECTION behaves as follows:
| |
| 1. If a thread is currently executing inside a CRITICAL region and another thread reaches that CRITICAL region and attempts to execute it, it will block until the first thread exits that CRITICAL region.
| |
| 2. It is illegal to branch into or out of a CRITICAL block.
| |
|
| |
| * ''atomic'': similar to ''critical section'', but advise the compiler to use special hardware instructions for better performance. Compilers may choose to ignore this suggestion from users and use ''critical section'' instead.
| |
| Format: #pragma omp atomic ''newline''
| |
| ''statement_expression''
| |
|
| |
| ATOMIC behaves as follows:
| |
| 1. Only to a single, immediately following statement.
| |
| 2. An atomic statement must follow a specific syntax.
| |
|
| |
| * ''ordered'': the structured block is executed in the order in which iterations would be executed in a sequential loop
| |
| Format: #pragma omp for ordered ''[clauses...]''
| |
| ''(loop region)''
| |
| #pragma omp ordered ''newline''
| |
| ''structured_block
| |
| (endo of loop region)''
| |
|
| |
| ORDERED behaves as follows:
| |
| 1. only appear in the dynamic extent of ''for'' or ''parallel for (C/C++)''.
| |
| 2. Only one thread is allowed in an ordered section at any time.
| |
| 3. It is illegal to branch into or out of an ORDERED block.
| |
| 4. A loop which contains an ORDERED directive, must be a loop with an ORDERED clause.
| |
|
| |
| * ''barrier'': each thread waits until all of the other threads of a team have reached this point. A work-sharing construct has an implicit barrier synchronization at the end.
| |
| Format: #pragma omp barrier ''newline''
| |
|
| |
| BARRIER behaves as follows:
| |
| 1. All threads in a team (or none) must execute the BARRIER region.
| |
| 2. The sequence of work-sharing regions and barrier regions encountered must be the same for every thread in a team.
| |
|
| |
| *''taskwait'': specifies that threads completing assigned work can proceed without waiting for all threads in the team to finish. In the absence of this clause, threads encounter a barrier synchronization at the end of the work sharing construct.
| |
| Format: #pragma omp taskwait ''newline''
| |
|
| |
| TASKWAIT behaves as follows:
| |
| 1. Placed only at a point where a base language statement is allowed.
| |
| 2. Not be used in place of the statement following an if, while, do, switch, or label.
| |
|
| |
| *''flush'': The FLUSH directive identifies a synchronization point at which the implementation must provide a consistent view of memory. Thread-visible variables are written back to memory at this point.
| |
| Format: #pragma omp flush ''(list) newline''
| |
|
| |
| FLUSH behaves as follows:
| |
| 1. The optional list contains a list of named variables that will be flushed in order to avoid flushing all variables.
| |
| 2. Implementations must ensure any prior modifications to thread-visible variables are visible to all threads after this point.
| |
|
| |
| =====Scheduling clauses=====
| |
| *''schedule(type, chunk)'': This is useful if the work sharing construct is a do-loop or for-loop. The iteration(s) in the work sharing construct are assigned to threads according to the scheduling method defined by this clause. The three types of scheduling are:
| |
| #''static'': Here, all the threads are allocated iterations before they execute the loop iterations. The iterations are divided among threads equally by default. However, specifying an integer for the parameter "chunk" will allocate "chunk" number of contiguous iterations to a particular thread.
| |
| #''dynamic'': Here, some of the iterations are allocated to a smaller number of threads. Once a particular thread finishes its allocated iteration, it returns to get another one from the iterations that are left. The parameter "chunk" defines the number of contiguous iterations that are allocated to a thread at a time.
| |
| #''guided'': A large chunk of contiguous iterations are allocated to each thread dynamically (as above). The chunk size decreases exponentially with each successive allocation to a minimum size specified in the parameter "chunk"
| |
| =====Initialization=====
| |
| * ''firstprivate'': the data is private to each thread, but initialized using the value of the variable using the same name from the master thread.
| |
| Format: firstprivate ''(list)''
| |
|
| |
| FIRSTPRIVATE variables behave as follows:
| |
| 1. Listed variables are initialized according to the value of their original objects prior to entry into the parallel or work-sharing construct.
| |
|
| |
| * ''lastprivate'': the data is private to each thread. The value of this private data will be copied to a global variable using the same name outside the parallel region if current iteration is the last iteration in the parallelized loop. A variable can be both ''firstprivate'' and ''lastprivate''.
| |
| Format: lastprivate ''(list)''
| |
|
| |
| * ''threadprivate'': The data is a global data, but it is private in each parallel region during the runtime. The difference between ''threadprivate'' and ''private'' is the global scope associated with threadprivate and the preserved value across parallel regions.
| |
| Format: #pragma omp threadprivate ''(list)''
| |
|
| |
| THREADPRIVATE variables behave as follows:
| |
| 1. On first entry to a parallel region, data in THREADPRIVATE variables and common blocks should be assumed undefined.
| |
| 2. The THREADPRIVATE directive must appear after every declaration of a thread private variable/common block.
| |
|
| |
| =====Reduction=====
| |
| * ''reduction'': the variable has a local copy in each thread, but the values of the local copies will be summarized (reduced) into a global shared variable. This is very useful if a particular operation (specified in "operator" for this particular clause) on a datatype that runs iteratively so that its value at a particular iteration depends on its value at a previous iteration. Basically, the steps that lead up to the operational increment are parallelized, but the threads gather up and wait before updating the datatype, then increments the datatype in order so as to avoid racing condition.
| |
| Format: reduction ''(operator: list)''
| |
|
| |
| REDUTION variables behave as follows:
| |
| 1. Variables in the list must be named scalar variables. They can not be array or structure type variables. They must also be declared SHARED in the enclosing context.
| |
| 2. Reduction operations may not be associative for real numbers.
| |
|
| |
| ====DOALL====
| |
|
| |
| In code 3.20, first it must include the header file ''omp.h'' which contains OpenMP function declarations. Next, A parallel region is started by #pragma omp parallel and we enclose this program bu curly brackets. We can use (setenv OMP_NUM_THREADS n) to specify the number of threads. Another way to determine the number of threads is directly calling a function (omp_set_numtheads (n)).
| |
| Code 3.20 only has one loop to execute and we want it to execute in parallel, so we combine the start of the parallel loop and the start of the parallel region with one directive ''#pragma omp parallel for''.
| |
|
| |
| '''Code 3.20 A DOALL parallelism example in OpenMP
| |
| '''#include''' <omp.h>
| |
| '''...'''
| |
| '''#pragma''' omp parallel //start of parallel region
| |
| '''{'''
| |
| '''...'''
| |
| '''#pragma''' omp parallel for default (shared)
| |
| '''for''' ( i = 0; i < n ; i++)
| |
| '''A[i]''' = A[i] + A[i] - 3.0;
| |
| '''}'''//end for parallel region
| |
|
| |
| Apparently, there is no loop-carried dependence in ''i'' loop. With OpenMP, we only need to insert the ''pragma'' directive ''parallel for''. The ''dafault(shared)'' clauses states that all variables within the scope of the loop are shared unless otherwise specified.
| |
|
| |
| ====DOACROSS====
| |
| We will now introduce how to implement DOACROSS in OpenMP. Here is an example code which has not been paralleled yet.
| |
|
| |
| '''Sample Code'''
| |
| 01: for(i=1; i< N; i++) {
| |
| 02: for(j=1; j<N; j++){
| |
| 03: a[i][j]=a[i-1][j]+a[i][j-1];
| |
| 04: }
| |
| 05: }
| |
|
| |
| From this sample code, obviously, there is dependence existing here.
| |
| a[i,j] -> T a[i+1, j+1]
| |
|
| |
| In OpenMP, DOALL parallel can be implemented by insert a “#pragma omp for” before the “for” structure in the source code. But there is not a pragma corresponding to DOACROSS parallel.
| |
|
| |
| When we implement DOACROSS, we use a shared array "_mylocks[threadid]" which is defined to store events of each thread. Besides, a private variable _counter0 is defined to indicate the event which current thread is waiting for. "mylock" indicates the total number of threads.
| |
| The number of threads is gotten by function "omp_get_num_threads()" and current thread's id is gotten by function "omp_get_thread_num()".
| |
|
| |
| *omp_get_num_threads(): Returns the number of threads that are currently in the team executing the parallel region from which it is called.
| |
| Format: #include <omp.h>
| |
| int omp_get_num_threads(void)
| |
|
| |
| OMP_GET_NUM_THREADS behaves as following:
| |
| 1. If this call is made from a serial portion of the program, or a nested parallel region that is serialized, it will return 1.
| |
| 2. The default number of threads is implementation dependent.
| |
|
| |
| *omp_get_thread_num(): Returns the thread number of the thread, within the team, making this call. This number will be between 0 and OMP_GET_NUM_THREADS-1. The master thread of the team is thread 0
| |
| Format: #include <omp.h>
| |
| int omp_get_thread_num(void)
| |
|
| |
| OMP_GET_THREAD_NUM behaves as followings:
| |
| 1. If called from a nested parallel region, or a serial region, this function will return 0.
| |
|
| |
| Now, let's see the code which has been paralleled and explanation.
| |
|
| |
| 01: int _mylocks[256]; //thread’s synchronized array
| |
| 02: #pragma omp parallel
| |
| 03: {
| |
| 04: int _counter0 = 1;
| |
| 05: int _my_id = omp_get_thread_num();
| |
| 06: int _my_nprocs= omp_get_num_threads();
| |
| 07: _mylocks[my_id] = 0;
| |
| 08: for(j_tile = 0; j_tile<N-1; j_tile+=M){
| |
| 09: if(_my_id>0) {
| |
| 10: do{
| |
| 11: #pragma omp flush(_mylock)
| |
| 12: } while(_mylock[myid-1]<_counter0);
| |
| 13: #pragma omp flush(a, _mylock)
| |
| 14: _counter0 += 1;
| |
| 15: }
| |
| 16: #pragma omp for nowait
| |
| 17: for(i=1; i< N; i++) {
| |
| 18: for(j=j_tile;j<j_tile+M;j++){
| |
| 19: a[i][j]=a[i-1][j]+a[i][j-1];
| |
| 20: }
| |
| 21: }
| |
| 22: _mylock[myid] += 1;
| |
| 23: #pragma omp flush(a, _mylock)
| |
| 24: }
| |
| 25: }
| |
|
| |
| We paralleled the original program in two steps.
| |
|
| |
| *First step: We divide i loop among the other four processors by inserting an OpenMP to construct “#programa omp for nowait” (line 16). Afterwards, each processor will take four interations of the loop i. The same to j loop. Assume the size of each block is 4. Each processor will execute four iterations of loop j. In order to let the total iterations be equal to the original program, j has to be enclosed in loop i. So, the new loop will be looked like ''for (j_tile = 2; j_tile <= 15; j_tile += 4)'', line 18.
| |
| The lower bound of loop j is set to j_tile and the upper bound will be j_tile+3. We will keep the other statement unchanged.
| |
|
| |
| *Second step: We are going to Synchronize the neighbor threads. After first step, the four processor will finish computing a block 4x4. If we parallel all these four processors, the dependence will be violated. So, we have to synchronized them by neighbors.
| |
| We set 4 variables as followings:
| |
| 1. A private variable: _my_nprocs = omp_get_num_threads(), which indicates the total number of threads that run corresponding parallel region.
| |
| 2. A private variable : _my_id = omp_get_thread_num(),which indicates the unique ID for current thread.
| |
| 3. A shared array:_mylocks[proc], is initialize by 0 for each element, which is used to indicate whether the thread of proc-1 has finish computing the current block.
| |
| 4. A private variable :_counter0, is initialize by 1, which indicate the block that current thread is waiting for.
| |
|
| |
| With the four variables, threads are synchronized:
| |
| The first thread continues to run with out waiting (line 9), because its thread ID is 0. Then all other thread can not go down after line 12. If the value in ''_mylocks[_my_id-1]'' is smaller than ''_counter0''.
| |
|
| |
| Otherwise, the block that the current thread is waiting for must have to be completed, and the current thread can go down to line 12, and mark the next block it will wait for by adding 1 to ''_counter0'' (line 14).
| |
|
| |
| When current thread finish its block, it will set that it
| |
| has finish a block by ''mylocks[proc]++''. Once the neighbor thread finds the value has been changed, it will continue running and so on. The below figure presents it to us.
| |
| [[Image:Synchorization.jpg]]
| |
|
| |
| ====DOPIPE====
| |
| Here is another example code and we are going to parallelize it in DOPIPE parallelism. There is a dependence, which is S2 -> T S1, existing in the sample code.
| |
| '''Sample Code'''
| |
| 01: for(i=1; i< N; i++) {
| |
| 02: S1: a[i]=b[i];
| |
| 03: S2: c[i]=c[i-1]+a[i];
| |
| 04:
| |
| 05: }
| |
| Now, let's see how to parallel the sample code to DOPIPE parallelism.
| |
| we still use a shared array "_mylocks[threadid]" which is defined to store events of each thread. Besides, a private variable _counter0 is defined to indicate the event which current thread is waiting for. "mylock" indicates the total number of threads.
| |
| The number of threads is got by function "omp_get_num_threads()" and current thread's id is got by function "omp_get_thread_num()".
| |
|
| |
| 01: int _mylocks[256]; //thread’s synchronized array
| |
| 02: #pragma omp parallel
| |
| 03: {
| |
| 04: int _counter0 = 1;
| |
| 05: int _my_id = omp_get_thread_num();
| |
| 06: int _my_nprocs= omp_get_num_threads();
| |
| 07: _mylocks[my_id] = 0;
| |
| 08: for(i_tile = 0; i_tile<N-1; i_tile+=M){
| |
| 09: if(_my_id>0) {
| |
| 10: do{
| |
| 11: #pragma omp flush(_mylock)
| |
| 12: } while(_mylock[myid-1]<_counter0);
| |
| 13: #pragma omp flush(a, _mylock)
| |
| 14: _counter0 += 1;
| |
| 15: }
| |
| 16: #pragma omp for nowait
| |
| 17: for(i=1; i< N; i++) {
| |
| 18: a[i]=b[i];
| |
| 19: }
| |
| 20: for(i=1; i< N; i++) {
| |
| 21: c[i]=c[i-1]+a[i];
| |
| 22: }
| |
| 23: _mylock[myid] += 1;
| |
| 24: #pragma omp flush(a, _mylock)
| |
| 25: }
| |
| 26: }
| |
|
| |
| Ideally, We parallelized the original program into two steps.
| |
|
| |
| *First step: We divide i loop among the other processors by inserting an OpenMP to construct “#programa omp for nowait” (line 16). Afterwards, each processor will take interations of the loop i. Now, there are two loop i existing and each loop i contains different statements. Also, we will keep other statements remained.
| |
|
| |
| *Second step: We are going to Synchronize the threads. After first step, processors will finish computing
| |
| a[i]=b[i]. If we parallel all the processors to do the second loop i, the dependence will be violated. So, we have to synchronized them by neighbors.
| |
| Still, we set 4 variables as followings:
| |
| 1. A private variable: _my_nprocs = omp_get_num_threads(), which indicates the total number of threads that run corresponding parallel region.
| |
| 2. A private variable : _my_id = omp_get_thread_num(),which indicates the unique ID for current thread.
| |
| 3. A shared array:_mylocks[proc], is initialize by 0 for each element, which is used to indicate whether the thread of proc-1 has finish computing the current block.
| |
| 4. A private variable :_counter0, is initialize by 1, which indicate the block that current thread is waiting for.
| |
|
| |
| When current thread finish its block, it will set that it has finish a block by ''mylocks[proc]++''. Once the processors finish their own block, the other processors will be able to get the value to use that value to execute in its statement and process that.
| |
|
| |
| ====Functional Parallelism====
| |
|
| |
| In order to introduce function parallelism, we want to execute some code section in parallel with another code section. We use code 3.21 to show two loops execute in parallel with respect to one another, although each loop is sequentially executed.
| |
|
| |
| '''Code''' 3.21 A function parallelism example in OpenMP
| |
| '''pragma''' omp parallel shared(A, B)private(i)
| |
| '''{'''
| |
| '''#pragma''' omp sections nowait
| |
| '''{'''
| |
| '''pragma''' omp section
| |
| '''for'''( i = 0; i < n ; i++)
| |
| '''A[i]''' = A[i]*A[i] - 4.0;
| |
| '''pragma''' omp section
| |
| '''for'''( i = 0; i < n ; i++)
| |
| '''B[i]''' = B[i]*B[i] - 9.0;
| |
| '''}'''//end omp sections
| |
| '''}'''//end omp parallel
| |
|
| |
| In code 3.21, there are two loops needed to be executed in parallel. We just need to insert two ''pragma omp section'' statements. Once we insert these two statements, those two loops will execute sequentially.
| |
|
| |
| ===Intel Thread Building Blocks===
| |
|
| |
| Intel Threading Building Blocks (Intel TBB) is a library that supports scalable
| |
| parallel programming using standard ISO C++ code. It does not require special
| |
| languages or compilers. It is designed to promote scalable data parallel programming.
| |
| The library consists of data structures and algorithms that allow a programmer to avoid some complications arising from the use of native threading packages such as POSIX threads, Windows threads, or the portable Boost Threads in which individual threads of execution are created, synchronized, and terminated manually. Instead the library abstracts access to the multiple processors by allowing the operations to be treated as "tasks," which are allocated to individual cores dynamically by the library's run-time engine, and by automating efficient use of the cache. This approach groups TBB in a family of solutions for parallel programming aiming to decouple the programming from the particulars of the underlying machine. Also, Intel Threading Building Blocks provides net results, which enables you to specify
| |
| parallelism more conveniently than using raw threads, and at the same time can
| |
| improve performance.
| |
|
| |
| ====Variables Scope====
| |
|
| |
| Intel TBB is a collection of components for parallel programming, here is the overview of the library contents:
| |
|
| |
| * Basic algorithms: parallel_for, parallel_reduce, parallel_scan
| |
| * Advanced algorithms: parallel_while, parallel_do,pipeline, parallel_sort
| |
| * Containers: concurrent_queue, concurrent_vector, concurrent_hash_map
| |
| * Scalable memory allocation: scalable_malloc, scalable_free, scalable_realloc, scalable_calloc, scalable_allocator, cache_aligned_allocator
| |
| * Mutual exclusion: mutex, spin_mutex, queuing_mutex, spin_rw_mutex, queuing_rw_mutex, recursive mutex
| |
| * Atomic operations: fetch_and_add, fetch_and_increment, fetch_and_decrement, compare_and_swap, fetch_and_store
| |
| * Timing: portable fine grained global time stamp
| |
| * Task Scheduler: direct access to control the creation and activation of tasks
| |
|
| |
| Then we will focus on some specific TBB variables.
| |
|
| |
| =====parallel_for=====
| |
|
| |
| Parallel_for is the template function that performs parallel iteration over a range of values. In Intel TBB, a lot of DOALL cases could be implemented by using this function. The syntax is as follows:
| |
| template<typename Index, typename Function>
| |
| Function parallel_for(Index first, Index_type last, Index step, Function f);
| |
| template<typename Range, typename Body>
| |
| void parallel_for( const Range& range, const Body& body, [, partitioner] );
| |
|
| |
| A parallel_for(first, last, step, f) represents parallel execution of the loop: "for( auto i=first; i<last; i+=step ) f(i);".
| |
|
| |
| =====parallel_reduce=====
| |
|
| |
| Function parallel_reduce computes reduction over a range. Syntax is as follows:
| |
| template<typename Range, typename Value, typename Func, typename Reduction>
| |
| Value parallel_reduce( const Range& range, const Value& identity, const Func& func, const Reduction& reduction );
| |
|
| |
| The functional form parallel_reduce(range,identity,func,reduction) performs a
| |
| parallel reduction by applying func to subranges in range and reducing the results
| |
| using binary operator reduction. It returns the result of the reduction. Parameter func
| |
| and reduction can be lambda expressions.
| |
|
| |
| =====parallel_scan=====
| |
|
| |
| This template function computes parallel prefix. Syntax is as follows:
| |
| template<typename Range, typename Body>
| |
| void parallel_scan( const Range& range, Body& body );
| |
|
| |
| template<typename Range, typename Body>
| |
| void parallel_scan( const Range& range, Body& body, const auto_partitioner& );
| |
|
| |
| template<typename Range, typename Body>
| |
| void parallel_scan( const Range& range, Body& body, const simple_partitioner& );
| |
|
| |
| A parallel_scan(range,body) computes a parallel prefix, also known as parallel
| |
| scan. This computation is an advanced concept in parallel computing that is
| |
| sometimes useful in scenarios that appear to have inherently serial dependences. A
| |
| further explanation will be given in the DOACROSS example.
| |
|
| |
| =====pipeline=====
| |
|
| |
| This class performs pipelined execution. Members as follows:
| |
| namespace tbb {
| |
| class pipeline {
| |
| public:
| |
| pipeline();
| |
| ~pipeline();
| |
| void add_filter( filter& f );
| |
| void run( size_t max_number_of_live_tokens );
| |
| void clear();
| |
| };
| |
| }
| |
|
| |
| A pipeline represents pipelined application of a series of filters to a stream of items.
| |
| Each filter operates in a particular mode: parallel, serial in order, or serial out of order. With a parallel filter,
| |
| we could implement DOPIPE parallelism.
| |
|
| |
| ====Reduction====
| |
|
| |
| The reduction in Intel TBB is implemented using parallel_reduce function. A parallel_reduce recursively splits the range into subranges and uses the splitting constructor to make one or more copies of the body for each thread. We use an example to illustrate this:
| |
|
| |
| #include "tbb/parallel_reduce.h"
| |
| #include "tbb/blocked_range.h"
| |
| using namespace tbb;
| |
| struct Sum {
| |
| float value;
| |
| Sum() : value(0) {}
| |
| Sum( Sum& s, split ) {value = 0;}
| |
| void operator()( const blocked_range<float*>& r ) {
| |
| float temp = value;
| |
| for( float* a=r.begin(); a!=r.end(); ++a ) {
| |
| temp += *a;
| |
| }
| |
| value = temp;
| |
| }
| |
| void join( Sum& rhs ) {value += rhs.value;}
| |
| };
| |
| float ParallelSum( float array[], size_t n ) {
| |
| Sum total;
| |
| parallel_reduce( blocked_range<float*>( array, array+n ), total );
| |
| return total.value;
| |
| }
| |
|
| |
| The above example sums the values in the array. The parallel_reduce will do the reduction within the range of (array, array+n), to split the working body, and then join them by the return value for each split.
| |
|
| |
| ====DOALL====
| |
| The implementation of DOALL parallelism in Intel TBB will involve Parallel_for function.
| |
| To better illustrate the usage, here we discuss a simple example. The following is the original code:
| |
|
| |
| void SerialApplyFoo( float a[], size_t n ) {
| |
| for( size_t i=0; i<n; ++i )
| |
| Foo(a[i]);
| |
| }
| |
|
| |
| After using Intel TBB, it could be switched to the following:
| |
|
| |
| #include "tbb/blocked_range.h"
| |
| #include "tbb/parallel_for.h"
| |
|
| |
| class ApplyFoo {
| |
| float *const my_a;
| |
| public:
| |
| void operator( )( const blocked_range<size_t>& r ) const {
| |
| float *a = my_a;
| |
| for( size_t i=r.begin(); i!=r.end( ); ++i )
| |
| Foo(a[i]);
| |
| }
| |
| ApplyFoo( float a[] ) :
| |
| my_a(a)
| |
| {}
| |
| };
| |
|
| |
| void ParallelApplyFoo( float a[], size_t n ) {
| |
| parallel_for(blocked_range<size_t>(0,n,The_grain_size_You_Pick), ApplyFoo(a) );
| |
| }
| |
|
| |
| The example is the simplest DOALL parallelism, similar to the one in the textbook, and execution graph will be very similar as the one in DOALL section above. But with the help of this simple illustration, the TBB code just gives you a flavor of how it would be implemented in Intel Threading Building Blocks.
| |
|
| |
| A little more to say, parallel_for takes an optional third argument to specify a partitioner, which I used "The_grain_size_You_Pick" to represent. If you want to manually divide the grain and assign the work to processors, you could specify that in the function. Or, you could use automatic grain provided TBB. The auto_partitioner provides an alternative that heuristically chooses the grain size so that you do not have to specify one. The heuristic attempts to limit overhead while still providing ample opportunities for load balancing. Then, the last three line of the TBB code above will be:
| |
|
| |
|
| void ParallelApplyFoo( float a[], size_t n ) {
| | ==Types of Parallelism== |
| parallel_for(blocked_range<size_t>(0,n), ApplyFoo(a), auto_partitioner( ) );
| |
| }
| |
|
| |
|
| ====DOACROSS==== | | ===Section Overview=== |
|
| |
|
| We could find a good example in Intel TBB to implement a DOACROSS with the help of parallel_scan. As stated in the parallel_scan section, this function computes a parallel prefix, also known as parallel
| | This section will give a brief overview of common types of parallel programming models. For more detailed information on this topic please see [http://pg-server.csc.ncsu.edu/mediawiki/index.php/CSC/ECE_506_Spring_2010/ch_3_yl THIS WIKI]. The following parallelisms will be covered here: DOALL, DOACROSS, DOPIPE, reduction, and functional parallelism |
| scan. This computation is an advanced concept in parallel computing which
| |
| could be helpful in scenarios that appear to have inherently serial dependences, which could be loop-carried dependences.
| |
|
| |
|
| Let's consider this scenario (which is actually the mathematical definition of parallel prefix):
| | ===DOALL Parallelism=== |
| T temp = id⊕;
| |
| for( int i=1; i<=n; ++i ) {
| |
| temp = temp ⊕ x[i];
| |
| y[i] = temp;
| |
| }
| |
|
| |
|
| When we implement this in TBB using parallel_scan, it becomes:
| | DOALL parallelism allows all iterations of a loop to be executed in parallel. There are no loop-carried dependencies.[[#References|<sup>[2]</sup>]] The following code is an example of a loop that could use DOALL parallelism to parallelis for the i loop [[#References|<sup>[3]</sup>]]: |
|
| |
|
| using namespace tbb;
| | for (i=0; i<n; i++) |
| class Body {
| | for (j=0; j< n; j++) |
| T sum;
| | S3: a[i][j] = a[i][j-1] + 1; |
| T* const y;
| |
| const T* const x;
| |
| public:
| |
| Body( T y_[], const T x_[] ) : sum(id⊕), x(x_), y(y_) {}
| |
| T get_sum() const {return sum;}
| |
| template<typename Tag>
| |
| void operator()( const blocked_range<int>& r, Tag ) {
| |
| T temp = sum;
| |
| for( int i=r.begin(); i<r.end(); ++i ) {
| |
| temp = temp ⊕ x[i];
| |
| if( Tag::is_final_scan() )
| |
| y[i] = temp;
| |
| }
| |
| sum = temp;
| |
| }
| |
| Body( Body& b, split ) : x(b.x), y(b.y), sum(id⊕) {}
| |
| void reverse_join( Body& a ) { sum = a.sum ⊕ sum;}
| |
| void assign( Body& b ) {sum = b.sum;}
| |
| };
| |
|
| |
|
| float DoParallelScan( T y[], const T x[], int n ) {
| | Note the lack of dependencies across the different iterations of the i loop. |
| Body body(y,x);
| |
| parallel_scan( blocked_range<int>(0,n), body );
| |
| return body.get_sum();
| |
| }
| |
|
| |
|
| It is the second part (function DoParallelScan) that we have to focus on.
| | [[Image:DOALL.jpg]] [[#References|<sup>[3]</sup>]] |
| | ===DOACROSS Parallelism=== |
| | Consider this the following loop[[#References|<sup>[3]</sup>]]: |
|
| |
|
| Actually, this example is just the scenario mentioned above that could take advantages of parallel_scan. The "inherently serial dependences" is taken care of by the functionality of parallel_scan. By computing the prefix, the serial code could be implemented in parallel with just one function.
| | for (i=1; i<=N; i++) { |
| | S: a[i] = a[i-1] + b[i] * c[i]; |
| | } |
| | It is not possible to use DOALL parallelism on this loop because of the loop-carried dependence of the “a” variable. But notice that the “b[i] * c[i]” portion of the code does not have any loop-carried dependencies. This is the situation needed to use DOACROSS parallelism. The following loop can be developed to use DOACROSS parallelism.[[#References|<sup>[3]</sup>]] |
|
| |
|
| ====DOPIPE==== | | post(0); |
| | for (i=1; i<=N; i++) { |
| | S1: temp = b[i] * c[i]; |
| | wait(i-1); |
| | S2: a[i] = a[i-1] + temp; |
| | post(i); |
| | } |
|
| |
|
| Pipeline class is the Intel TBB that performs pipelined execution. A pipeline represents pipelined application of a series of filters to a stream of items. Each filter operates in a particular mode: parallel, serial in order, or serial out of order. So this class can be used to implement a DOPIPE parallelism.
| | Each iteration of “b[i] * c[i]” can be performed in parallel, then as soon as the loop-carried dependence on a is satisfied S2 can execute. |
|
| |
|
| Here is a comparatively complex example about pipeline implementation. Also, if we look carefully, this is an example with both DOPIPE and DOACROSS:
| | [[Image:DOACROSS.jpg]] [[#References|<sup>[3]</sup>]] |
|
| |
|
| #include <iostream> | | ===DOPIPE parallelism=== |
| #include "tbb/pipeline.h"
| | DOPIPE parallelism is another method of parallelism for loops that have loop-carried dependences that uses pipelining. Consider the following loop [[#References|<sup>[3]</sup>]]: |
| #include "tbb/tbb_thread.h"
| |
| #include "tbb/task_scheduler_init.h"
| |
| using namespace tbb;
| |
| char InputString[] = "abcdefg\n";
| |
| class InputFilter: public filter {
| |
| char* my_ptr;
| |
| public:
| |
| void* operator()(void*) {
| |
| if (*my_ptr)
| |
| return my_ptr++;
| |
| else
| |
| return NULL;
| |
| }
| |
| InputFilter() :
| |
| filter( serial_in_order ), my_ptr(InputString) {}
| |
| };
| |
| class OutputFilter: public thread_bound_filter {
| |
| public:
| |
| void* operator()(void* item) {
| |
| std::cout << *(char*)item;
| |
| return NULL;
| |
| }
| |
| OutputFilter() : thread_bound_filter(serial_in_order) {}
| |
| };
| |
| void RunPipeline(pipeline* p) {
| |
| p->run(8);
| |
| }
| |
| int main() {
| |
| // Construct the pipeline
| |
| InputFilter f;
| |
| OutputFilter g;
| |
| pipeline p;
| |
| p.add_filter(f);
| |
| p.add_filter(g);
| |
| // Another thread initiates execution of the pipeline
| |
| tbb_thread t(RunPipeline,&p);
| |
| // Process the thread_bound_filter with the current thread.
| |
| while (g.process_item()!=thread_bound_filter::end_of_stream)
| |
| continue;
| |
| // Wait for pipeline to finish on the other thread.
| |
| t.join();
| |
| return 0;
| |
| }
| |
|
| |
|
| The example above shows a pipeline with two filters where the second filter is a thread_bound_filter serviced by the main thread. The main thread does the following after constructing the pipeline:
| | for (i=2; i<=N; i++) { |
| 1. Start the pipeline on another thread. | | S1: a[i] = a[i-1] + b[i]; |
| 2. Service the thread_bound_filter until it reaches end_of_stream.
| | S2: c[i] = c[i] + a[i]; |
| 3. Wait for the other thread to finish.
| | } |
|
| |
|
| ===POSIX Threads===
| | In this example there is both a loop-carried dependence on S1 and a loop-independent dependence between S1 and S2. These dependencies require that S1[i] executes before S1[i+1] and S2[i]. This leads to the following parallelized code [[#References|<sup>[3]</sup>]]: |
|
| |
|
| POSIX Threads, or Pthreads, is a POSIX standard for threads. The standard, POSIX.1c, Threads extensions (IEEE Std 1003.1c-1995), defines an API for creating and manipulating threads.
| | for (i=2; i<=N; i++) { |
| | a[i] = a[i-1] + b[i]; |
| | post(i); |
| | } |
| | for (i=2; i<=N; i++) { |
| | wait(i); |
| | c[i] = c[i] + a[i]; |
| | } |
|
| |
|
| ====Variable Scopes====
| | This code satisfies all of the above requirements. |
| Pthreads defines a set of C programming language types, functions and constants. It is implemented with a pthread.h header and a thread library.
| |
|
| |
|
| There are around 100 Pthreads procedures, all prefixed "pthread_". The subroutines which comprise the Pthreads API can be informally grouped into four major groups:
| | [[Image:DOPIPE.jpg]] [[#References|<sup>[3]</sup>]] |
|
| |
|
| * '''Thread management:''' Routines that work directly on threads - creating, detaching, joining, etc. They also include functions to set/query thread attributes (joinable, scheduling etc.) E.g.pthread_create(), pthread_join().
| | ===Functional parallelism=== |
| * '''Mutexes:''' Routines that deal with synchronization, called a "mutex", which is an abbreviation for "mutual exclusion". Mutex functions provide for creating, destroying, locking and unlocking mutexes. These are supplemented by mutex attribute functions that set or modify attributes associated with mutexes. E.g. pthread_mutex_lock(); pthread_mutex_trylock(); pthread_mutex_unlock().
| | Functional parallelism is used when a loop contains statements that are independent of one another. It provides a modest amount of parallelism and it does not grow with input size. However, it can be used in conjunction with data parallelism (i.e. DOALL, DOACROSS, etc). Consider the following loop [[#References|<sup>[3]</sup>]]: |
| * '''Condition variables:''' Routines that address communications between threads that share a mutex. Based upon programmer specified conditions. This group includes functions to create, destroy, wait and signal based upon specified variable values. Functions to set/query condition variable attributes are also included. E.g. pthread_cond_signal(); pthread_cond_broadcast(); pthread_cond_wait(); pthread_cond_timedwait();pthread_cond_reltimedwait_np().
| |
| * '''Synchronization:''' Routines that manage read/write locks and barriers. E.g. pthread_rwlock_rdlock(); pthread_rwlock_tryrdlock(); pthread_rwlock_wrlock();pthread_rwlock_trywrlock(); pthread_rwlock_unlock();pthread_barrier_init(); pthread_barrier_wait()
| |
|
| |
|
| ====DOALL==== | | for (i=0; i<n; i++) { |
| | S1: a[i] = b[i+1] * a[i-1]; |
| | S2: b[i] = b[i] * coef; |
| | S3: c[i] = 0.5 * (c[i] + a[i]); |
| | S4: d[i] = d[i-1] * d[i]; |
| | } |
|
| |
|
| The following is a simple code example in C, as DOALL parallelism, to print out each threads' ID#.
| | Statement S4 has no dependence on any of the other statements in the loop, therefore it can be executed in parallel of statements S1, S2, and S3 [[#References|<sup>[3]</sup>]]: |
|
| |
|
| #include <pthread.h>
| | for (i=0; i<n; i++) { |
| #include <stdio.h>
| | S1: a[i] = b[i+1] * a[i-1]; |
| #include <stdlib.h>
| | S2: b[i] = b[i] * coef; |
| #define NUM_THREADS 5
| | S3: c[i] = 0.5 * (c[i] + a[i]); |
| | | } |
| void *PrintHello(void *threadid)
| | for (i=0; i<n; i++) { |
| {
| | S4: d[i] = d[i-1] * d[i]; |
| long tid; | | } |
|
| |
| tid = (long)threadid; | |
| printf("Hello World! It's me, thread #%ld!\n", tid); | |
| pthread_exit(NULL);
| |
| }
| |
|
| |
| int main (int argc, char *argv[])
| |
| {
| |
| pthread_t threads[NUM_THREADS];
| |
| | |
| int rc;
| |
| long t;
| |
| for(t=0; t<NUM_THREADS; t++){
| |
| printf("In main: creating thread %ld\n", t);
| |
| rc = pthread_create(&threads[t], NULL, PrintHello, (void *)t);
| |
| | |
| if (rc){
| |
| printf("ERROR; return code from pthread_create() is %d\n", rc);
| |
| exit(-1);
| |
| }
| |
| }
| |
| pthread_exit(NULL);
| |
| }
| |
|
| |
|
| This loop contains only single statement which doesn't cross the iterations, so each iteration could be considered as a parallel task.
| | ===Reduction=== |
| ====DOACROSS==== | | Reduction can be used on operations that are both commutative and associative such as addition multiplication, and logical operations. An example of this is if a sum of products needs to be performed on a matrix. The matrix can be divided into smaller portions and assign one processor to work on each portion of the matrix. After all of the processors have completed their tasks, the individual sums can be combined into a global sum. [[#References|<sup>[4]</sup>]] |
|
| |
|
| When it comes to using Pthreads to implement DOACROSS, it could express functional parallelism easily, but make the parallelism unnecessarily complicated. See an example below: from '''POSIX Threads Programming''' by Blaise Barney
| | ==Why Synchronization is Needed== |
|
| |
|
| #include <pthread.h> | | When using any of the above parallel programming models, synchronization is needed to guarantee accuracy of the overall program. The following are a few example situations where synchronization will be needed. |
| #include <stdio.h> | | *The code following the parallelized loop requires that all of the parallel processes be completed before advancing. It cannot be triggered simply by one of the processes completing. |
| #include <stdlib.h>
| | *A portion of code in the middle of a parallelized section MUST be executed in a very particular order so that global variables used across processes get read and written in the proper order. This is known as the critical section |
| #define NUM_THREADS | | *Multiple processes must update a global variable in such a way that one process does not overwrite the updates of a different process. (i.e. SUM = SUM + <process update>) |
|
| | This is just a few examples. Every architecture implements synchronization in a unique way using different types of mechanisms. The following section will highlight various architectures’ synchronization mechanisms. |
| void *BusyWork(void *t)
| |
| {
| |
| int i;
| |
| long tid;
| |
| double result=0.0;
| |
| tid = (long)t;
| |
| printf("Thread %ld starting...\n",tid);
| |
| for (i=0; i<1000000; i++)
| |
| {
| |
| result = result + sin(i) * tan(i);
| |
| }
| |
| printf("Thread %ld done. Result = %e\n",tid, result);
| |
| pthread_exit((void*) t);
| |
| }
| |
|
| |
| int main (int argc, char *argv[])
| |
| {
| |
| pthread_t thread[NUM_THREADS];
| |
| pthread_attr_t attr;
| |
| int rc;
| |
| long t;
| |
| void *status;
| |
|
| |
| /* Initialize and set thread detached attribute */
| |
| pthread_attr_init(&attr);
| |
| pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
| |
|
| |
| for(t=0; t<NUM_THREADS; t++) {
| |
| printf("Main: creating thread %ld\n", t);
| |
| rc = pthread_create(&thread[t], &attr, BusyWork, (void *)t);
| |
| if (rc) {
| |
| printf("ERROR; return code from pthread_create()
| |
| is %d\n", rc);
| |
| exit(-1);
| |
| }
| |
| }
| |
| | |
| /* Free attribute and wait for the other threads */
| |
| pthread_attr_destroy(&attr);
| |
| for(t=0; t<NUM_THREADS; t++) {
| |
| rc = pthread_join(thread[t], &status);
| |
| if (rc) {
| |
| printf("ERROR; return code from pthread_join()
| |
| is %d\n", rc);
| |
| exit(-1);
| |
| }
| |
| printf("Main: completed join with thread %ld having a status
| |
| of %ld\n",t,(long)status);
| |
| }
| |
|
| |
| printf("Main: program completed. Exiting.\n"); | |
| pthread_exit(NULL);
| |
| } | |
|
| |
|
| This example demonstrates how to "wait" for thread completions by using the Pthread join routine. Since some implementations of Pthreads may not create threads in a joinable state, the threads in this example are explicitly created in a joinable state so that they can be joined later.
| |
|
| |
| ====DOPIPE====
| |
| There is examples of using Posix Threads to implement DOPIPE parallelism, but unnecessarily complex. Due to the long length, we won't provide it here. If the reader is interested, it could be found in <li>[http://homepage.mac.com/dbutenhof/Threads/code/pipe.c Pthreads DOPIPE example]</li>
| |
|
| |
| ===Comparison among the three===
| |
|
| |
| ====A unified example====
| |
|
| |
| We use a simple parallel example from [http://sourceforge.net Sourceforge.net] to show how it will be implemented in the three packages, namely, POSIX Threads, Intel TBB, OpenMP, to show some commonalities and differences among them.
| |
|
| |
| Following is the original code:
| |
|
| |
| Grid1 *g = new Grid1(0, n+1);
| |
| Grid1IteratorSub it(1, n, g);
| |
| DistArray x(g), y(g);
| |
| ...
| |
| float e = 0;
| |
| ForEach(int i, it,
| |
| x(i) += ( y(i+1) + y(i-1) )*.5;
| |
| e += sqr( y(i) ); )
| |
| ...
| |
|
| |
| Then we are going to show the implementations in different packages, and also make a brief summary of the three packages.
| |
|
| |
| =====In POSIX Thread=====
| |
|
| |
| POSIX Thread: Symmetric multi processing, e.g. SMP multi-processor computers, multi-core processors, virtual shared memory computer.
| |
|
| |
| Data layout: A single global memory. Each thread reads global shared data and writes to a private fraction of global data.
| |
|
| |
| A simplified translation of the example parallel-for loop is given below.
| |
|
| |
| Global declaration:
| |
|
| |
| #include <pthread.h>
| |
| float *x, *y;
| |
| float vec[8];
| |
| int nn, pp;
| |
|
| |
| thread code:
| |
|
| |
| void *sub1(void *arg) {
| |
| int p = (int)arg;
| |
| float e_local = 0;
| |
| for (int i=1+(nn*p)/pp; i<1+(nn*(p+1))/pp; ++i) {
| |
| x[i] += ( y[i+1] + y[i-1] )*.5;
| |
| e_local += y[i] * y[i];
| |
| }
| |
| vec[p] = e_local;
| |
| return (void*) 0;
| |
| }
| |
|
| |
| main code:
| |
|
| |
| x = new float[n+1];
| |
| y = new float[n+1];
| |
| ...
| |
| float e = 0;
| |
| int p_threads = 8;
| |
| nn = n-1;
| |
| pp = p_threads;
| |
| pthread_t threads[8];
| |
| pthread_attr_t attr;
| |
| pthread_attr_init(&attr);
| |
| for (int p=0; p<p_threads; ++p)
| |
| pthread_create(&threads[p], &attr,
| |
| sub1, (void *)p);
| |
| for (int p=0; p<p_threads; ++p) {
| |
| pthread_join(threads[p], NULL);
| |
| e += vec[p];
| |
| }
| |
| ...
| |
| delete[] x, y;
| |
|
| |
| =====In Intel Threading Building Blocks=====
| |
|
| |
| Intel TBB: A C++ library for thread programming, e.g. SMP multi-processor computers, multi-core processors, virtual shared memory computer.
| |
|
| |
| Data layout: A single global memory. Each thread reads global shared data and writes to a private fraction of global data.
| |
|
| |
| Translation of the example parallel-for loop is given below.
| |
|
| |
| Global:
| |
| #include "tbb/task_scheduler_init.h"
| |
| #include "tbb/blocked_range.h"
| |
| #include "tbb/parallel_reduce.h"
| |
| #include "tbb/cache_aligned_allocator.h"
| |
| using namespace tbb;
| |
|
| |
| thread code:
| |
| struct sub1 {
| |
| float ee;
| |
| float *x, *y;
| |
| sub1(float *xx, float *yy) : ee(0), x(xx), y(yy) {}
| |
| sub1(sub1& s, split) { ee = 0; x = s.x; y = s.y; }
| |
| void operator() (const blocked_range<int> & r){
| |
| float e = ee;
| |
| for (int i = r.begin(); i!= r.end(); ++i) {
| |
| x[i] += ( y[i+1] + y[i-1] )*.5;
| |
| e += y[i] * y[i];
| |
| }
| |
| ee = e;
| |
| }
| |
| void join(sub1& s) { ee += s.ee; }
| |
| };
| |
|
| |
| main code:
| |
| task_scheduler_init init;
| |
| ...
| |
| float e;
| |
| float *x = cache_aligned_allocator<float>().allocate(n+1);
| |
| float *y = cache_aligned_allocator<float>().allocate(n+1);
| |
| ...
| |
| sub1 s(x, y);
| |
| parallel_reduce(blocked_range<int>(1, n, 1000), s);
| |
| e = s.ee;
| |
| ...
| |
| cache_aligned_allocator<float>().deallocate(x, n+1);
| |
| cache_aligned_allocator<float>().deallocate(y, n+1);
| |
|
| |
| =====In OpenMP shared memory parallel code annotations=====
| |
|
| |
| OpenMP: Usually automatic paralleization with a run-time system based on a thread library.
| |
|
| |
| A simplified translation of the example parallel-for loop is given below.
| |
|
| |
| Global:
| |
| float e;
| |
|
| |
| main code:
| |
| float *x = new float[n+1];
| |
| float *y = new float[n+1];
| |
| ...
| |
| e = 0;
| |
| #pragma omp for reduction(+:e)
| |
| for (int i=1; i<n; ++i) {
| |
| x[i] += ( y[i+1] + y[i-1] )*.5;
| |
| e += y[i] * y[i];
| |
| }
| |
| ...
| |
| delete[] x, y;
| |
|
| |
| ====Summary: Difference among them====
| |
|
| |
| *Pthreads works for all the parallelism and could express functional parallelism easily, but it needs to build specialized synchronization primitives and explicitly privatize variables, means there is more effort needed to switch a serial program in to parallel mode.
| |
|
| |
| *OpenMP can provide many performance enhancing features, such as atomic, barrier and flush synchronization primitives. It is very simple to use OpenMP to exploit DOALL parallelism, but the syntax for expressing functional parallelism is awkward.
| |
|
| |
| *Intel TBB relies on generic programming, it performs better with custom iteration spaces or complex reduction operations. Also, it provides generic parallel patterns for parallel while-loops, data-flow pipeline models, parallel sorts and prefixes, so it's better in cases that go beyond loop-based parallelism.
| |
|
| |
| Below is a table that illustrates the differences [[#References|<sup>[16]</sup>]]
| |
| {| align="center cellpadding="4"
| |
|
| |
| |-
| |
| !Type of Parallelism
| |
| !Posix Threads
| |
| !Intel® TBB
| |
| !OpenMP 2.0
| |
| !OpenMp 3.0
| |
|
| |
| |-
| |
| !DOALL
| |
| |align="center"|Yes
| |
| |align="center"|Yes
| |
| |align="center"|Yes
| |
| |align="center"|Yes
| |
|
| |
| |-
| |
| !DOACROSS
| |
| |align="center"|Yes
| |
| |align="center"|No
| |
| |align="center"|No
| |
| |align="center"|No
| |
|
| |
| |-
| |
| !DOPIPE
| |
| |align="center"|Yes
| |
| |align="center"|Yes
| |
| |align="center"|No
| |
| |align="center"|No
| |
|
| |
| |-
| |
| ! Reduction
| |
| |align="center"|No
| |
| |align="center"|Yes
| |
| |align="center"|No
| |
| |align="center"|No
| |
|
| |
| |-
| |
| ! Functional Parallelism
| |
| |align="center"|No
| |
| |align="center"|No
| |
| |align="center"|Yes
| |
| |align="center"|Yes
| |
|
| |
| |}
| |
|
| |
|
| ==Synchronization Mechanisms== | | ==Synchronization Mechanisms== |
|
| |
|
| ===Overveiw=== | | ===Section Overview=== |
| | |
| In order to accomplish the above parallelizations in a real system, the memory must be carefully orchestrated such that no information gets corrupted. Every architecture handles synchronizing data from parallel processors slightly differently. This section is going to look at different architectures and highlight a few of the mechanisms that are used to achieve this memory synchorization.
| |
|
| |
|
| | In order to accomplish the above parallelizations in a real system, the memory must be carefully orchestrated such that no information gets corrupted. Every architecture handles synchronizing data from parallel processors slightly differently. This section is going to look at different architectures and highlight a few of the mechanisms that are used to achieve this memory synchronization. |
|
| |
|
| ===IA-64=== | | ===IA-64=== |
| IA-64 is an Intel architecture that is mainly used in Itanium processors. | | IA-64 is an Intel architecture that is mainly used in Itanium processors. |
| ====Spinlock==== | | ====Spinlock==== |
| the spinlock is used to guard against multiple accesses to the critical section at the same time. The critical section is a section of code that must be executed in sequential order, it cannot be parallelized. Therefore, when a parallel process comes across an occupied critical section the process will “spin” until the lock is released. [[#References|<sup>[12]</sup>]] | | the spinlock is used to guard against multiple accesses to the critical section at the same time. The critical section is a section of code that must be executed in sequential order. It cannot be parallelized. Therefore, when a parallel process comes across an occupied critical section the process will “spin” until the lock is released. [[#References|<sup>[5]</sup>]] |
|
| |
|
| // available. If it is 1, another process is in the critical section. | | // available. If it is 1, another process is in the critical section. |
| Line 887: |
Line 130: |
| st8.rel(lock) = r0 ;; //release the lock | | st8.rel(lock) = r0 ;; //release the lock |
|
| |
|
| The above code demonstrates how a spin lock is used. Once the process gets to a spin lock, it will check to see if the lock is available, if it is not, then the process will proceed into the spin loop where it will continuously check to see if the lock is available. Once it finds out the lock is available, it will attempt to obtain the lock. If another process obtains the lock first, then the process will branch back into the spin loop and continue to wait. | | The above code demonstrates how a spin lock is used. Once the process gets to a spin lock, it will check to see if the lock is available. If it is not, then the process will proceed into the spin loop where it will continuously check to see if the lock is available. Once it finds out the lock is available, it will attempt to obtain the lock. If another process obtains the lock first, then the process will branch back into the spin loop and continue to wait. |
|
| |
|
| ====Barrier==== | | ====Barrier==== |
|
| |
|
| A barrier is a common mechanism used to hold up processes until all processes can get to the same point. The mechanism is useful in kinds of different parallelisms (DOALL, DOACROSS, DOPIPE, reduction, and functional parallelism) This architecture uses a unique form of the barrier mechanism called the sense-reversing barrier. The idea behind this barrier is to prevent race conditions. If a process from the “next” instance of the barrier races ahead while slow processes from the current barrier are leaving, the fast processes could trap the slow processes at the “next” barrier and thus corrupting the memory synchronization. [[#References|<sup>[12]</sup>]] | | A barrier is a common mechanism used to hold up processes until all processes can get to the same point. The mechanism is useful in various kinds of different parallelisms (DOALL, DOACROSS, DOPIPE, reduction, and functional parallelism) This architecture uses a unique form of the barrier mechanism called the sense-reversing barrier. The idea behind this barrier is to prevent race conditions. If a process from the “next” instance of the barrier races ahead while slow processes from the current barrier are leaving, the fast processes could trap the slow processes at the “next” barrier and thus corrupting the memory synchronization. [[#References|<sup>[5]</sup>]] |
|
| |
|
| ====Dekker’s Algorithm==== | | ====Dekker’s Algorithm==== |
|
| |
|
| Dekker’s Algorithm uses variables to indicate which processers are using which resources. It basically arbitrates for a resource using these variables. Every processor has a flag that indicates when it is in the critical section. So when a processor is getting ready to enter the critical section it will set its flag to one, then it will check to make sure that all of the other processor flags are zero, then it will proceed into the section. This behavior is demonstrated in the code below. It is a two-way multiprocessor system, so there are two processor flags, flag_me and flag_you. [[#References|<sup>[12]</sup>]] | | Dekker’s Algorithm uses variables to indicate which processors are using which resources. It basically arbitrates for a resource using these variables. Every processor has a flag that indicates when it is in the critical section. So when a processor is getting ready to enter the critical section it will set its flag to one, then it will check to make sure that all of the other processor flags are zero, then it will proceed into the section. This behavior is demonstrated in the code below. It is a two-way multiprocessor system, so there are two processor flags, flag_me and flag_you. [[#References|<sup>[5]</sup>]] |
|
| |
|
| // The flag_me variable is zero if we are not in the synchronization and | | // The flag_me variable is zero if we are not in the synchronization and |
| Line 921: |
Line 164: |
| ====Lamport’s Algorithm==== | | ====Lamport’s Algorithm==== |
|
| |
|
| Lamport’s Algorithm is similar to a spinlock with the addition of a fairness mechanism that keeps track of the order in which processes request the shared resource and provides access to the shared resource in the same order. It makes use of two variable x and y and a shared array, b. The example below shows example code for this algorithm. [[#References|<sup>[12]</sup>]] | | Lamport’s Algorithm is similar to a spinlock with the addition of a fairness mechanism that keeps track of the order in which processes request the shared resource and provides access to the shared resource in the same order. It makes use of two variable x and y and a shared array, b. The example below shows example code for this algorithm. [[#References|<sup>[5]</sup>]] |
|
| |
|
| // The proc_id variable holds a unique, non-zero id for the process that | | // The proc_id variable holds a unique, non-zero id for the process that |
| Line 972: |
Line 215: |
|
| |
|
| ====Locked Atomic Operation==== | | ====Locked Atomic Operation==== |
| This is the main mechanism for this architecture to manage shared data structures such as semaphores and system segments. The process uses the following three interdependent mechanisms to implement the locked atomic operation: [[#References|<sup>[13]</sup>]] | | This is the main mechanism for this architecture to manage shared data structures such as semaphores and system segments. The process uses the following three interdependent mechanisms to implement the locked atomic operation: [[#References|<sup>[6]</sup>]] |
| * Guaranteed atomic operations. | | * Guaranteed atomic operations. |
| * Bus locking, using the LOCK# signal and the LOCK instruction prefix. | | * Bus locking, using the LOCK# signal and the LOCK instruction prefix. |
| Line 978: |
Line 221: |
|
| |
|
| =====Guaranteed Atomic Operation===== | | =====Guaranteed Atomic Operation===== |
| The following are guaranteed to be carried out automatically: [[#References|<sup>[13]</sup>]] | | The following are guaranteed to be carried out automatically: [[#References|<sup>[6]</sup>]] |
| Reading or writing a byte. | | * Reading or writing a byte. |
| * Reading or writing a word aligned on a 16-bit boundary. | | * Reading or writing a word aligned on a 16-bit boundary. |
| * Reading or writing a doubleword aligned on a 32-bit boundary.The P6 family processors guarantee that the following additional memory operations will always be carried out atomically: | | * Reading or writing a doubleword aligned on a 32-bit boundary.The P6 family processors guarantee that the following additional memory operations will always be carried out atomically: |
| Line 991: |
Line 234: |
| ===Linux Kernel=== | | ===Linux Kernel=== |
|
| |
|
| Linux Kernel is referred to as an “architecture”, however it is fairly unconventional in that it is an open source operating system that has full access to the hardware. It uses many common synchronization mechanisms, so it will be considered here. [[#References|<sup>[15]</sup>]] | | Linux Kernel is referred to as an “architecture”, however it is fairly unconventional in that it is an open source operating system that has full access to the hardware. It uses many common synchronization mechanisms, so it will be considered here. [[#References|<sup>[8]</sup>]] |
|
| |
|
| ====Busy-waiting lock==== | | ====Busy-waiting lock==== |
| Line 1,020: |
Line 263: |
| ====_syncthreads==== | | ====_syncthreads==== |
|
| |
|
| The _syncthreads operation can be used at the end of a parallel section as a sort of “barrier” mechanicm. It is necessary to ensure the accuracy of the memory. In the following example, there are two calls to _syncthreads. They are both necessary to ensure the expected results are obtained. Without it, myArray[tid] could end up being either 2 or the original value of myArray[] depending on when the read and write take place.[[#References|<sup>[14]</sup>]] | | The _syncthreads operation can be used at the end of a parallel section as a sort of “barrier” mechanicm. It is necessary to ensure the accuracy of the memory. In the following example, there are two calls to _syncthreads. They are both necessary to ensure the expected results are obtained. Without it, myArray[tid] could end up being either 2 or the original value of myArray[] depending on when the read and write take place.[[#References|<sup>[7]</sup>]] |
|
| |
|
| // myArray is an array of integers located in global or shared | | // myArray is an array of integers located in global or shared |
| Line 1,035: |
Line 278: |
| ... | | ... |
| { | | { |
|
| |
| ===PowerPC=== | | ===PowerPC=== |
|
| |
|
| PowerPC is an IBM architecture that stands for Performance Optimization With Enhanced RISC-Performance Computing. It is a RISC architecture that was originally designed for PCs, however it has grown into the embedded and high-performance space. [[#References|<sup>[18]</sup>]] | | PowerPC is an IBM architecture that stands for Performance Optimization With Enhanced RISC-Performance Computing. It is a RISC architecture that was originally designed for PCs, however it has grown into the embedded and high-performance space. [[#References|<sup>[10]</sup>]] |
|
| |
|
| ====Isync==== | | ====Isync==== |
|
| |
|
| isync is an instruction that guarantees that before any code proceeding after the isync instruction can execute, all of the code preceding it has already completed. It also ensures that any cache block invalidations instructions that were executed before the isync have been carried out with respect to the processor executing the isync instruction. It then causes any prefetched instructions to be discarded. [[#References|<sup>[17]</sup>]] | | isync is an instruction that guarantees that before any code proceeding after the isync instruction can execute, all of the code preceding it has already completed. It also ensures that any cache block invalidations instructions that were executed before the isync have been carried out with respect to the processor executing the isync instruction. It then causes any prefetched instructions to be discarded. [[#References|<sup>[9]</sup>]] |
|
| |
|
| ====Memory Barrier Instructions==== | | ====Memory Barrier Instructions==== |
|
| |
|
| Memory Barrier Instructions can be used to control the order in which storage access are performed. [[#References|<sup>[17]</sup>]] | | Memory Barrier Instructions can be used to control the order in which storage access are performed. [[#References|<sup>[9]</sup>]] |
|
| |
|
| =====HeavyWeight sync===== | | =====HeavyWeight sync===== |
| Line 1,055: |
Line 297: |
|
| |
|
| =====Enforce In-order Execution of I/O===== | | =====Enforce In-order Execution of I/O===== |
| The Enforce In-order Execution of I/O, or eieio, instruction is a memory barrier that creates an ordering function for the storage accesses caused by LOADs and STOREs. These instructions are split into two groups: [[#References|<sup>[17]</sup>]] | | The Enforce In-order Execution of I/O, or eieio, instruction is a memory barrier that creates an ordering function for the storage accesses caused by LOADs and STOREs. These instructions are split into two groups: [[#References|<sup>[9]</sup>]] |
|
| |
|
| 1. Loads and stores to storage that is both Caching Inhibited and Guarded, and stores to main storage caused by stores to storage that is Write Through Required | | 1. Loads and stores to storage that is both Caching Inhibited and Guarded, and stores to main storage caused by stores to storage that is Write Through Required |
| Line 1,062: |
Line 304: |
|
| |
|
| For the first group the ordering done by the memory barrier for accesses in this set is not cumulative. For the second group the ordering done by the memory barrier for accesses in this set is cumulative. | | For the first group the ordering done by the memory barrier for accesses in this set is not cumulative. For the second group the ordering done by the memory barrier for accesses in this set is cumulative. |
|
| |
|
| |
|
| ===Cell Broadband Engine=== | | ===Cell Broadband Engine=== |
| Cell Broadband Engine Architecture, also referred to as Cell or Cell BE, is an IBM architecture whose first major application was in Sony’s PlayStation 3. Cell has streamlined coprocessing elements which is great for fast multimedia and vector processing applications. [[#References|<sup>[20]</sup>]] | | Cell Broadband Engine, also referred to as Cell or Cell BE, is an IBM architecture whose first major application was in Sony’s PlayStation 3. Cell has streamlined coprocessing elements which is great for fast multimedia and vector processing applications. [[#References|<sup>[12]</sup>]] |
| | |
|
| |
|
| This architecture is interesting because it uses a shared memory model in which the LOADs and STOREs use a “weakly consistent” storage model. Meaning that, the sequence in which any of the following orders are executed may be different from each other: [[#References|<sup>[19]</sup>]] | | This architecture is interesting because it uses a shared memory model in which the LOADs and STOREs use a “weakly consistent” storage model. Meaning that, the sequence in which any of the following orders are executed may be different from each other: [[#References|<sup>[11]</sup>]] |
|
| |
|
| * The order of any processor element (PPE or SPE) performing storage access | | * The order of any processor element (PPE or SPE) performing storage access |
| Line 1,077: |
Line 317: |
|
| |
|
| ====Fence==== | | ====Fence==== |
| After all previous issued commands within the same “tag group” have been performed the fence instruction can be issued. If there is a command that is issued after the fence command, it might be executed before the fence command. [[#References|<sup>[19]</sup>]] | | After all previous issued commands within the same “tag group” have been performed the fence instruction can be issued. If there is a command that is issued after the fence command, it might be executed before the fence command. [[#References|<sup>[11]</sup>]] |
|
| |
|
| ====Barrier==== | | ====Barrier==== |
| After all previous issued commands have been performed, the barrier command and all of the instructions after the barrier command can then be executed. [[#References|<sup>[19]</sup>]] | | After all previous issued commands have been performed, the barrier command and all of the instructions after the barrier command can then be executed. [[#References|<sup>[11]</sup>]] |
|
| |
|
|
| |
|
| Line 1,086: |
Line 326: |
| ==References== | | ==References== |
| <ol> | | <ol> |
| <li>[http://openmp.org/wp/about-openmp/ OpenMP.org]</li> | | <li>[http://pg-server.csc.ncsu.edu/mediawiki/index.php/CSC/ECE_506_Spring_2010/ch_3_yl WIKI reference for parallel programming models]</li> |
| <li>[https://docs.google.com/viewer?a=v&pid=gmail&attid=0.1&thid=126f8a391c11262c&mt=application%2Fpdf&url=https%3A%2F%2Fmail.google.com%2Fmail%2F%3Fui%3D2%26ik%3Dd38b56c94f%26view%3Datt%26th%3D126f8a391c11262c%26attid%3D0.1%26disp%3Dattd%26realattid%3Df_g602ojwk0%26zw&sig=AHIEtbTeQDhK98IswmnVSfrPBMfmPLH5Nw An Optimal Abtraction Model for Hardware Multithreading in Modern Processor Architectures]</li>
| | <li>[http://pg-server.csc.ncsu.edu/mediawiki/index.php/CSC/ECE_506_Spring_2010/ch_3_jb/Parallel_Programming_Model_Support WIKI reference for DOALL parallelism]</li> |
| <li>[http://www.threadingbuildingblocks.org/uploads/81/91/Latest%20Open%20Source%20Documentation/Reference.pdf Intel Threading Building Blocks 2.2 for Open Source Reference Manual]</li>
| | <li>[http://courses.ncsu.edu/csc506/lec/001/lectures/notes/lec5.doc Lecture 5 from NC State's ECE/CSC506]</li> |
| <li>[http://www.csc.ncsu.edu/faculty/efg/506/s10/ NCSU CSC 506 Parallel Computing Systems]</li> | | <li>[http://courses.ncsu.edu/csc506/lec/001/lectures/notes/lec6.doc Lecture 6 from NC State's ECE/CSC506]</li> |
| <li>[http://parallel-for.sourceforge.net/tbb.html Sourceforge.net]</li>
| |
| <li>[https://computing.llnl.gov/tutorials/openMP/ OpenMP]</li> | |
| <li>[http://www.computer.org/portal/web/csdl/doi/10.1109/SNPD.2009.16 Barrier Optimization for OpenMP Program]</li>
| |
| <li>[http://cs.anu.edu.au/~Alistair.Rendell/sc02/module3.pdf Performance Programming: Theory, Practice and Case Studies]</li> | |
| <li>[http://software.intel.com/en-us/articles/intel-threading-building-blocks-openmp-or-native-threads/ Intel® Threading Building Blocks, OpenMP, or native threads?]</li>
| |
| <li>[https://computing.llnl.gov/tutorials/pthreads/#Joining POSIX Threads Programming by Blaise Barney, Lawrence Livermore National Laboratory]</li>
| |
| <li>[http://homepage.mac.com/dbutenhof/Threads/source.html Programing with POSIX Threads source code]</li>
| |
| <li>[http://refspecs.freestandards.org/IA64-softdevman-vol2.pdf IA-64 Software Development Manual]</li> | | <li>[http://refspecs.freestandards.org/IA64-softdevman-vol2.pdf IA-64 Software Development Manual]</li> |
| <li>[http://refspecs.freestandards.org/IA32-softdevman-vol3.pdf IA-32 Software Development Manual]</li> | | <li>[http://refspecs.freestandards.org/IA32-softdevman-vol3.pdf IA-32 Software Development Manual]</li> |
| <li>[http://developer.download.nvidia.com/compute/cuda/3_2_prod/toolkit/docs/CUDA_C_Programming_Guide.pdf CUDA Programming Guide]</li> | | <li>[http://developer.download.nvidia.com/compute/cuda/3_2_prod/toolkit/docs/CUDA_C_Programming_Guide.pdf CUDA Programming Guide]</li> |
| <li>[http://www.google.com/url?sa=t&source=web&cd=6&ved=0CEQQFjAF&url=http%3A%2F%2Flinuxindore.com%2Fdownloads%2Fdownload%2Fdata-structures%2Flinux-kernel-arch&ei=jxZWTaGTNI34sAPWm-ScDA&usg=AFQjCNG9UOAz7rHfwUDfayhr50M87uNOYA&sig2=azvo4h85RkoNHcZUtNIkJw Linux Kernel Architecture Overveiw]</li> | | <li>[http://www.google.com/url?sa=t&source=web&cd=6&ved=0CEQQFjAF&url=http%3A%2F%2Flinuxindore.com%2Fdownloads%2Fdownload%2Fdata-structures%2Flinux-kernel-arch&ei=jxZWTaGTNI34sAPWm-ScDA&usg=AFQjCNG9UOAz7rHfwUDfayhr50M87uNOYA&sig2=azvo4h85RkoNHcZUtNIkJw Linux Kernel Architecture Overveiw]</li> |
| <li>[http://pg-server.csc.ncsu.edu/mediawiki/index.php/CSC/ECE_506_Spring_2010/ch_3_jb/Parallel_Programming_Model_Support Spring 2010 NC State ECE/CSC506 Chapter 3 wiki]</li>
| |
| <li>[http://download.boulder.ibm.com/ibmdl/pub/software/dw/library/es-ppcbook2.zip PowerPC Architecture Book]</li> | | <li>[http://download.boulder.ibm.com/ibmdl/pub/software/dw/library/es-ppcbook2.zip PowerPC Architecture Book]</li> |
| <li>[http://www.google.com/url?sa=t&source=web&cd=1&ved=0CCEQFjAA&url=http%3A%2F%2Fen.wikipedia.org%2Fwiki%2FPowerPC&ei=77RYTejKFZSisQOm6-GiDA&usg=AFQjCNFt0LpxmNviHKFxCur-amK9HAG08Q&sig2=Kmm9RzJY-4AlG66AwWxlRA Wikipedia information on PowerPC]</li> | | <li>[http://www.google.com/url?sa=t&source=web&cd=1&ved=0CCEQFjAA&url=http%3A%2F%2Fen.wikipedia.org%2Fwiki%2FPowerPC&ei=77RYTejKFZSisQOm6-GiDA&usg=AFQjCNFt0LpxmNviHKFxCur-amK9HAG08Q&sig2=Kmm9RzJY-4AlG66AwWxlRA Wikipedia information on PowerPC]</li> |
Overview
The main goal of this wiki is to explore synchronization mechanisms in various architectures. These mechanisms are used to maintain program “correctness” and prevent data corruption when parallelism is employed by a system. This wiki will first give a brief description of various parallel programming models that could be using the synchronization mechanisms, which will be covered later in the wiki.
Types of Parallelism
Section Overview
This section will give a brief overview of common types of parallel programming models. For more detailed information on this topic please see THIS WIKI. The following parallelisms will be covered here: DOALL, DOACROSS, DOPIPE, reduction, and functional parallelism
DOALL Parallelism
DOALL parallelism allows all iterations of a loop to be executed in parallel. There are no loop-carried dependencies.[2] The following code is an example of a loop that could use DOALL parallelism to parallelis for the i loop [3]:
for (i=0; i<n; i++)
for (j=0; j< n; j++)
S3: a[i][j] = a[i][j-1] + 1;
Note the lack of dependencies across the different iterations of the i loop.
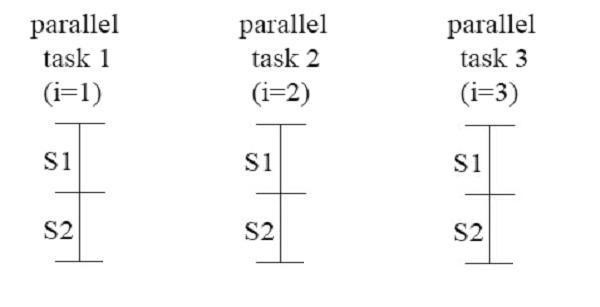 [3]
[3]
DOACROSS Parallelism
Consider this the following loop[3]:
for (i=1; i<=N; i++) {
S: a[i] = a[i-1] + b[i] * c[i];
}
It is not possible to use DOALL parallelism on this loop because of the loop-carried dependence of the “a” variable. But notice that the “b[i] * c[i]” portion of the code does not have any loop-carried dependencies. This is the situation needed to use DOACROSS parallelism. The following loop can be developed to use DOACROSS parallelism.[3]
post(0);
for (i=1; i<=N; i++) {
S1: temp = b[i] * c[i];
wait(i-1);
S2: a[i] = a[i-1] + temp;
post(i);
}
Each iteration of “b[i] * c[i]” can be performed in parallel, then as soon as the loop-carried dependence on a is satisfied S2 can execute.
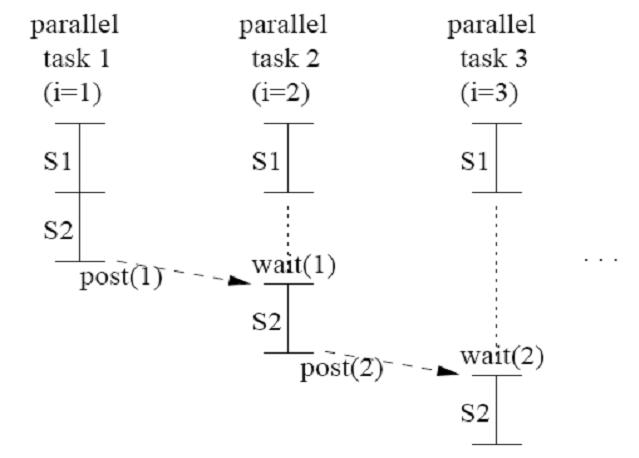 [3]
[3]
DOPIPE parallelism
DOPIPE parallelism is another method of parallelism for loops that have loop-carried dependences that uses pipelining. Consider the following loop [3]:
for (i=2; i<=N; i++) {
S1: a[i] = a[i-1] + b[i];
S2: c[i] = c[i] + a[i];
}
In this example there is both a loop-carried dependence on S1 and a loop-independent dependence between S1 and S2. These dependencies require that S1[i] executes before S1[i+1] and S2[i]. This leads to the following parallelized code [3]:
for (i=2; i<=N; i++) {
a[i] = a[i-1] + b[i];
post(i);
}
for (i=2; i<=N; i++) {
wait(i);
c[i] = c[i] + a[i];
}
This code satisfies all of the above requirements.
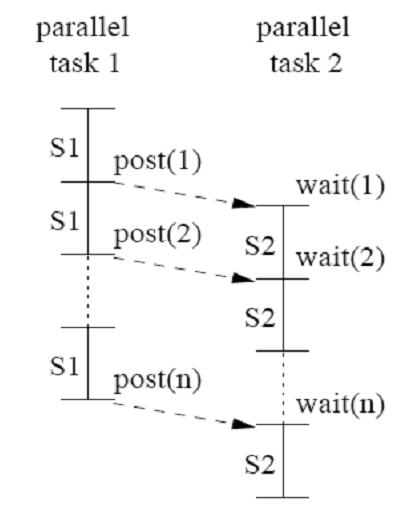 [3]
[3]
Functional parallelism
Functional parallelism is used when a loop contains statements that are independent of one another. It provides a modest amount of parallelism and it does not grow with input size. However, it can be used in conjunction with data parallelism (i.e. DOALL, DOACROSS, etc). Consider the following loop [3]:
for (i=0; i<n; i++) {
S1: a[i] = b[i+1] * a[i-1];
S2: b[i] = b[i] * coef;
S3: c[i] = 0.5 * (c[i] + a[i]);
S4: d[i] = d[i-1] * d[i];
}
Statement S4 has no dependence on any of the other statements in the loop, therefore it can be executed in parallel of statements S1, S2, and S3 [3]:
for (i=0; i<n; i++) {
S1: a[i] = b[i+1] * a[i-1];
S2: b[i] = b[i] * coef;
S3: c[i] = 0.5 * (c[i] + a[i]);
}
for (i=0; i<n; i++) {
S4: d[i] = d[i-1] * d[i];
}
Reduction
Reduction can be used on operations that are both commutative and associative such as addition multiplication, and logical operations. An example of this is if a sum of products needs to be performed on a matrix. The matrix can be divided into smaller portions and assign one processor to work on each portion of the matrix. After all of the processors have completed their tasks, the individual sums can be combined into a global sum. [4]
Why Synchronization is Needed
When using any of the above parallel programming models, synchronization is needed to guarantee accuracy of the overall program. The following are a few example situations where synchronization will be needed.
- The code following the parallelized loop requires that all of the parallel processes be completed before advancing. It cannot be triggered simply by one of the processes completing.
- A portion of code in the middle of a parallelized section MUST be executed in a very particular order so that global variables used across processes get read and written in the proper order. This is known as the critical section
- Multiple processes must update a global variable in such a way that one process does not overwrite the updates of a different process. (i.e. SUM = SUM + <process update>)
This is just a few examples. Every architecture implements synchronization in a unique way using different types of mechanisms. The following section will highlight various architectures’ synchronization mechanisms.
Synchronization Mechanisms
Section Overview
In order to accomplish the above parallelizations in a real system, the memory must be carefully orchestrated such that no information gets corrupted. Every architecture handles synchronizing data from parallel processors slightly differently. This section is going to look at different architectures and highlight a few of the mechanisms that are used to achieve this memory synchronization.
IA-64
IA-64 is an Intel architecture that is mainly used in Itanium processors.
Spinlock
the spinlock is used to guard against multiple accesses to the critical section at the same time. The critical section is a section of code that must be executed in sequential order. It cannot be parallelized. Therefore, when a parallel process comes across an occupied critical section the process will “spin” until the lock is released. [5]
// available. If it is 1, another process is in the critical section.
//
spin_lock:
mov ar.ccv = 0 // cmpxchg looks for avail (0)
mov r2 = 1 // cmpxchg sets to held (1)
spin:
ld8 r1 = [lock] ;; // get lock in shared state
cmp.ne p1, p0 = r1, r2 // is lock held (ie, lock == 1)?
(p1) br.cond.spnt spin ;; // yes, continue spinning
cmpxchg8.acqrl = [lock], r2 // attempt to grab lock
cmp.ne p1, p0 = r1, r2 // was lock empty?
(p1) br.cond.spnt spin ;; // bummer, continue spinning
cs_begin:
// critical section code goes here...
cs_end:
st8.rel(lock) = r0 ;; //release the lock
The above code demonstrates how a spin lock is used. Once the process gets to a spin lock, it will check to see if the lock is available. If it is not, then the process will proceed into the spin loop where it will continuously check to see if the lock is available. Once it finds out the lock is available, it will attempt to obtain the lock. If another process obtains the lock first, then the process will branch back into the spin loop and continue to wait.
Barrier
A barrier is a common mechanism used to hold up processes until all processes can get to the same point. The mechanism is useful in various kinds of different parallelisms (DOALL, DOACROSS, DOPIPE, reduction, and functional parallelism) This architecture uses a unique form of the barrier mechanism called the sense-reversing barrier. The idea behind this barrier is to prevent race conditions. If a process from the “next” instance of the barrier races ahead while slow processes from the current barrier are leaving, the fast processes could trap the slow processes at the “next” barrier and thus corrupting the memory synchronization. [5]
Dekker’s Algorithm
Dekker’s Algorithm uses variables to indicate which processors are using which resources. It basically arbitrates for a resource using these variables. Every processor has a flag that indicates when it is in the critical section. So when a processor is getting ready to enter the critical section it will set its flag to one, then it will check to make sure that all of the other processor flags are zero, then it will proceed into the section. This behavior is demonstrated in the code below. It is a two-way multiprocessor system, so there are two processor flags, flag_me and flag_you. [5]
// The flag_me variable is zero if we are not in the synchronization and
// critical section code and non-zero otherwise; flag_you is similarly set
// for the other processor. This algorithm does not retry access to the
// resource if there is contention.
dekker:
mov r1 = 1 ;; // my_flag = 1 (i want access)
st8 [flag_me] = r1
mf ;; // make st visible first
ld8 r2 = [flag_you] ;; // is other's flag 0?
cmp.eq p1, p0 = 0, r2
(p1)
br.cond.spnt cs_skip ;; // if not, resource in use
cs_begin:
// critical section code goes here...
cs_end:
cs_skip:
st8.rel[flag_me] = r0 ;; // release lock
Lamport’s Algorithm
Lamport’s Algorithm is similar to a spinlock with the addition of a fairness mechanism that keeps track of the order in which processes request the shared resource and provides access to the shared resource in the same order. It makes use of two variable x and y and a shared array, b. The example below shows example code for this algorithm. [5]
// The proc_id variable holds a unique, non-zero id for the process that
// attempts access to the critical section. x and y are the synchronization
// variables that indicate who is in the critical section and who is attempting
// entry. ptr_b_1 and ptr_b_id point at the 1'st and id'th element of b[].
//
lamport:
ld8 r1 = [proc_id] ;; // r1 = unique process id
start:
st8 [ptr_b_id] = r1 // b[id] = "true"
st8 [x] = r1 // x = process id
mf // MUST fence here!
ld8 r2 = [y] ;;
cmp.ne p1, p0 = 0, r2;; // if (y !=0) then...
(p1) st8 [ptr_b_id] = r0 // ... b[id] = "false"
(p1) br.cond.sptk wait_y // ... wait until y == 0
st8 [y] = r1 // y = process id
mf
ld8 r3 = [x] ;;
cmp.eq p1, p0 = r1, r3 ;; // if (x == id) then..
(p1) br.cond.sptk cs_begin // ... enter critical section
st8 [ptr_b_id] = r0 // b[id] = "false"
ld8 r3 = [ptr_b_1] // r3 = &b[1]
mov ar.lc = N-1 ;; // lc = number of processors - 1
wait_b:
ld8 r2 = [r3] ;;
cmp.ne p1, p0 = r1, r2 // if (b[j] != 0) then...
(p1) br.cond.spnt wait_b ;; // ... wait until b[j] == 0
add r3 = 8, r3 // r3 = &b[j+1]
br.cloop.sptk wait_b ;; // loop over b[j] for each j
ld8 r2 = [y] ;; // if (y != id) then...
cmp.ne p1, p2 = 0, r2
(p1) br.cond.spnt wait_y
br start // back to start to try again
cs_begin:
// critical section code goes here...
cs_end:
st8 [y] = r0 // release the lock
st8.rel[ptr_b_id] = r0 ;; // b[id] = "false"
IA-32
IA-32 is an Intel architecture that is also known as x86. This is a very widely used architecture.
Locked Atomic Operation
This is the main mechanism for this architecture to manage shared data structures such as semaphores and system segments. The process uses the following three interdependent mechanisms to implement the locked atomic operation: [6]
- Guaranteed atomic operations.
- Bus locking, using the LOCK# signal and the LOCK instruction prefix.
- Cache coherency protocols that insure that atomic operations can be carried out on cached data structures (cache lock). This mechanism is present in the P6 family processors.
Guaranteed Atomic Operation
The following are guaranteed to be carried out automatically: [6]
- Reading or writing a byte.
- Reading or writing a word aligned on a 16-bit boundary.
- Reading or writing a doubleword aligned on a 32-bit boundary.The P6 family processors guarantee that the following additional memory operations will always be carried out atomically:
- Reading or writing a quadword aligned on a 64-bit boundary. (This operation is also guaranteed on the Pentium® processor.)
- 16-bit accesses to uncached memory locations that fit within a 32-bit data bus.
- 16-, 32-, and 64-bit accesses to cached memory that fit within a 32-Byte cache line.
Bus Locking
A LOCK signal is asserted automatically during certain critical sections in order to lock the system bus and grant control to the process executing the critical section. This signal will disallow control of this bus by any other process while the LOCK is engaged.
Linux Kernel
Linux Kernel is referred to as an “architecture”, however it is fairly unconventional in that it is an open source operating system that has full access to the hardware. It uses many common synchronization mechanisms, so it will be considered here. [8]
Busy-waiting lock
Spinlocks
This mechanism is very similar to the mechanism described in the IA-64 architecture. It is a mechanism used to manage access to a critical section of code. If a process tries to access the critical section and is rejected it will sit and “spin” while it waits for the lock to be released.
Rwlocks
This is a special kind of spinlock. It is for protected structures that are frequently read, but rarely written. This lock allows multiple reads in parallel, which can increase efficiency if process are not having to sit and wait in order to merely carry out a read function. Like before however, one write is allowed at a time with no reads done in parallel
Brlocks
This is a super fast read/write lock, but it has a write-side penalty. The main advantage of this lock is to prevent cache “ping-pong” in a multiple read case.
Sleeper locks
Semiphores
A semaphore is special variable that acts similar to a lock. If the semaphore can be acquired then the process can proceed into the critical section. If the semaphore cannon be acquired, then the process is “put to sleep” and the processor is then used for another process. This means the processes cache is saved off in a place where it can be retrieved when the process is “woken up”. Once the semaphore is available the “sleeping” process is woken up and obtains the semaphore and proceeds in to the critical section.
CUDA
CUDA, or Compute Unified Device Architecture, is an Nvidia architecture which is the computing engine for their graphics processors.
_syncthreads
The _syncthreads operation can be used at the end of a parallel section as a sort of “barrier” mechanicm. It is necessary to ensure the accuracy of the memory. In the following example, there are two calls to _syncthreads. They are both necessary to ensure the expected results are obtained. Without it, myArray[tid] could end up being either 2 or the original value of myArray[] depending on when the read and write take place.[7]
// myArray is an array of integers located in global or shared
// memory
__global__ void MyKernel(int* result) {
int tid = threadIdx.x;
...
int ref1 = myArray[tid];
__syncthreads();
myArray[tid + 1] = 2;
__syncthreads();
int ref2 = myArray[tid];
result[tid] = ref1 * ref2;
...
{
PowerPC
PowerPC is an IBM architecture that stands for Performance Optimization With Enhanced RISC-Performance Computing. It is a RISC architecture that was originally designed for PCs, however it has grown into the embedded and high-performance space. [10]
Isync
isync is an instruction that guarantees that before any code proceeding after the isync instruction can execute, all of the code preceding it has already completed. It also ensures that any cache block invalidations instructions that were executed before the isync have been carried out with respect to the processor executing the isync instruction. It then causes any prefetched instructions to be discarded. [9]
Memory Barrier Instructions
Memory Barrier Instructions can be used to control the order in which storage access are performed. [9]
HeavyWeight sync
This memory barrier creates an ordering function for the storage accesses that are associated with all of the instructions that are executed by the processor executing the sync instruction.
LightWeight sync
This memory barrier creates an ordering function for the storage accesses caused by LOAD and STORE instructions that are executed by the processor executing the sync instruction. Also, this instruction must execute on the specified storage location in storage that is neither a Write Through Required nor a Caching Inhibited.
Enforce In-order Execution of I/O
The Enforce In-order Execution of I/O, or eieio, instruction is a memory barrier that creates an ordering function for the storage accesses caused by LOADs and STOREs. These instructions are split into two groups: [9]
1. Loads and stores to storage that is both Caching Inhibited and Guarded, and stores to main storage caused by stores to storage that is Write Through Required
2. Stores to storage that is Memory Coherence Required and is neither Write Through Required nor Caching Inhibited
For the first group the ordering done by the memory barrier for accesses in this set is not cumulative. For the second group the ordering done by the memory barrier for accesses in this set is cumulative.
Cell Broadband Engine
Cell Broadband Engine, also referred to as Cell or Cell BE, is an IBM architecture whose first major application was in Sony’s PlayStation 3. Cell has streamlined coprocessing elements which is great for fast multimedia and vector processing applications. [12]
This architecture is interesting because it uses a shared memory model in which the LOADs and STOREs use a “weakly consistent” storage model. Meaning that, the sequence in which any of the following orders are executed may be different from each other: [11]
- The order of any processor element (PPE or SPE) performing storage access
- The order in which the accesses are performed with respect to another processor element
- The order in which the accesses are performed in main storage
It is important that the accesses to the shared memory happen in the correct program order or information could be lost or corrupted. In order to ensure that this doesn’t happen the following memory barrier instructions are used:
Fence
After all previous issued commands within the same “tag group” have been performed the fence instruction can be issued. If there is a command that is issued after the fence command, it might be executed before the fence command. [11]
Barrier
After all previous issued commands have been performed, the barrier command and all of the instructions after the barrier command can then be executed. [11]
References
- WIKI reference for parallel programming models
- WIKI reference for DOALL parallelism
- Lecture 5 from NC State's ECE/CSC506
- Lecture 6 from NC State's ECE/CSC506
- IA-64 Software Development Manual
- IA-32 Software Development Manual
- CUDA Programming Guide
- Linux Kernel Architecture Overveiw
- PowerPC Architecture Book
- Wikipedia information on PowerPC
- IBM cell Cell Architecture Book
- Wikipedia information on Cell


