CSC/ECE 517 Fall 2013/ch1 1w47 ka: Difference between revisions
| Line 116: | Line 116: | ||
==References == | ==References == | ||
Specific references: | Specific references: | ||
<ref>[http://research.google.com/archive/mapreduce-osdi04-slides/index-auto-0004.html Example: Count word occurrences]. Research.google.com. Retrieved on 2013-09-18.</ref> | |||
General References: | |||
*http://www.slideshare.net/vastydeep/ruby-rails-no-sql-and-big-data | *http://www.slideshare.net/vastydeep/ruby-rails-no-sql-and-big-data | ||
*http://www.pikasoft.com/journal/2011/1/2/a-quick-redis-key-value-example-for-the-holidays.html | *http://www.pikasoft.com/journal/2011/1/2/a-quick-redis-key-value-example-for-the-holidays.html | ||
Revision as of 06:34, 10 October 2013
Big Data in Rails applications
This wiki discusses the implementation and usage of Ruby on Rails (RoR) for Big Data for its analysis and storage using different technologies.
Introduction to Big Data
With the increase in data size it becomes difficult to store the data in relational databases and also processing the data becomes very time consuming. Even if it is feasible to store the data on multiple servers, it becomes difficult to visualize the data all together since it is spread over multiple servers and processing time is also very large. Hence there arises a need of storing and retrieving huge amount of data effectively which involves massive parallel processing to fetch a huge amount of data in less time. This process of storing huge amount of data on multiple servers and processing that data which is not possible using traditional database processing techniques is called big data analysis and this collection of large data sets is called big data.
There are number of frameworks which support big data analysis and storage. To name a few we have Redis, Riak, MongoDB, Cassandra, Neo4J and the biggest of all Hadoop. All of them are based on different datastores. Different types of Data stores are as follows:
- Key-Value Data Store
- Document Data Stores
- Graph Data Stores
- Map Reduce
Key Value Data Store:
Key-Value Data Store is similar to hash table storage where a record is accessed using the key. Hence it is very fast but for complex data it is very difficult to use. Redis and Riak are based on key-value data stores. Example of key value data store is as follow:
you have a key in the left column and a value on the right side.
{
Name Mark
Age 20
Size Large
}
Document Data Store:
Document Data Store is a database which is used for storing, retrieving and managing documents. Each document has a predefined structure and it is uniquely represented by a document key which helps in accessing and storing the document. Each document is similar to a row in relational database. The only difference being each row has a fixed number of attributes(columns) whereas in the documents the number of attributes may be different. MongoDB and Cassandra are document Data stores. Example of Document Data Store:
{
name: "larry"
unityId: "larryp"
}
Graph Data Store:
Graph Data Store is a database in which data is represented by nodes and edges. Lookup of elements is possible using pointers to adjacent elements and hence index look-up is not possible. Neo4J uses graph data store. Example of graph data store can be viewed in the file.
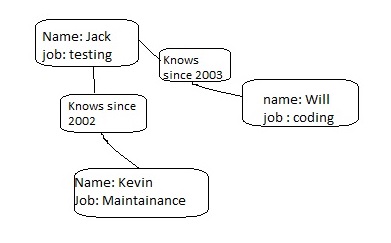

MapReduce Data Store:
MapReduce is a program which can be used to retrieve data from a cluster of data nodes using parallel processing. Map() function delegates the work to different data nodes in the cluster and reduce function performs operations on the data retrieved. Hadoop uses the map reduce technology for efficient data storage and retrieval.<ref>Example: Count word occurrences. Research.google.com. Retrieved on 2013-09-18.</ref>
Example of MapReduce Data Store:
function map(String name, String document):
// name: document name
// document: document contents
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for each pc in partialCounts:
sum += ParseInt(pc)
emit (word, sum)
Rails and Riak
Raik is a NoSQL database that was designed manly for speed of retrieval. As the data becomes complex it becomes difficult to store using key value pair. Riak was developed using programming language Erlang, while supporting a variety of additional language drivers such as Python, Java, PHP and Ruby. To use Riak in the application, first Erlang needs to be installed and then riak.
Put
gem 'ripple', :git => 'http://github.com/seancribbs/ripple.git' gem 'curb'
in the .gemfile of the project and run bundle install.
Next add Ripple into or config/database.yml:
ripple:
development:
port: 8098
host: localhost
and in all model classes put the following line:
require 'ripple'
class xyz
include Ripple::Document
statement x
statement y
end
After this start riak by going to "path where riak is stored/bin" and running the riak start command.
Now the riak is running and all the CRUD operations will be successfully performed.
Rais and Redis
Redis is a extremely quick, key value data store that allows storage of different data types like strings,lists, hashes and sets.Redis keeps all the data in RAM and it periodially writes to disk providing persistence. As a first step install redis source and run make command. Then start the rails server using following command:
./redis-server
To use redis install redis gem
gem install redis
In the .gemfile put
gem 'redis'
then run bundle install.
Now if the object needs to be saved than a connection object has to be created. For this generate a module as follows:
module RedisMod @@redis_connection = Redis.new def self.conn @@redis_connection end
Now in the model class to save a model object we first need to generate a key as redis is a key-value data store. So first gnerate a key and assign the object to be saved to the key and call conn function to save the record as follows:
def save #make generate key function using the logic you want generate_key unless @key return false unless valid? # store the key/value pair with @object being the object to be saved. RedisMod.conn[@key] = @object true end
References
Specific references: <ref>Example: Count word occurrences. Research.google.com. Retrieved on 2013-09-18.</ref>
General References:
- http://www.slideshare.net/vastydeep/ruby-rails-no-sql-and-big-data
- http://www.pikasoft.com/journal/2011/1/2/a-quick-redis-key-value-example-for-the-holidays.html
- http://www.pikasoft.com/journal/2010/7/31/nosql-on-the-cloud-our-first-application.html
- http://jit.nuance9.com/2010/07/ruby-192-rails-3-riak-and-ripple.html
- http://www.pikasoft.com/journal/2011/1/9/nosql-next-up-hadoop-and-cloudera.html
- http://en.wikipedia.org/wiki/Data_store