CSC/ECE 506 Fall 2007/wiki1 7 a1
Shared address space is an important class of the multiprocessors where all processors share a global memory. Communication between tasks running on different processors is performed through writing to and reading from the global memory. All interprocessor coordination and synchronization is also accomplished via the global memory. A shared memory computer system consists of a set of independent processors, a set of memory modules, and an interconnection network as shown in Figure below.
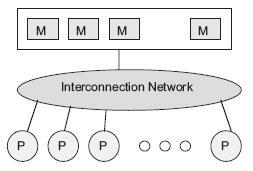

Current high-performance multiprocessor platforms may be broken into two categories: distributed address-space and shared address-space. For programs running on a distributed address-space multiprocessor, data visible on one processing unit is not visible on the remaining processor units. In contrast, hardware mechanisms in high performance shared address-space environments ensure that all data is in principle visible to all processors. While a shared address-space can offer programmability advantages and better performance for fine-grained applications, the very mechanisms that create those advantages appear to prevent the machines from scaling to large numbers of processors.
To scale beyond the limits of traditional shared address space architectures, hybrids of shared and distributed architectures are becoming more prevalent. These architectures allow users to take advantage of two or more address spaces to gain the scalability of distributed architectures while retaining the benefits of the shared address-space architecture. Memory is split into global, which hardware keeps coherent, and strictly local, which is left incoherent. Application programmers are given a mechanism for specifying, at a very high level, data that would benefit from localization – being moved from global to local memory. This transparency in memory partitioning takes place through improved compiler allocation mechanisms than the traditional hardware devices. The following are benefits of localizing otherwise remote memory accesses.
1. Faster access to localized data.
2. Elimination of redundant protocol traffic.
3. Elimination of locking/contention for written shared data.
A trend in application design is the use of vector instructions. This allows programs to deliver more fine grain tasks which capitalize on the parallel processing nature of a shared address space architecture. Vector instructions, also known as SIMD (single intruction multiple data), have been optimized on a series of recent architectures including the cell processor in Toshiba/Sony's PlayStation 3 game console. The PS3 cell processor consists of one scalar and eight vector processors.
Evolution of Interconnect Technology
The effectiveness of the shared memory approach depends on the latency incurred on the memory access as well as the bandwidth of the data transfer that can be supported. The interconnection network in a shared-memory multiprocessor has evolved over a decade to provide better aggregate bandwidth when more processors are added without increasing cost too much. Shared memory systems can be designed using bus-based or switch-based interconnection networks. The simplest network for shared memory systems is the bus and moreover the bus/cache architecture alleviates the need for expensive multiported memories and interface circuitry as well as the need to adopt a message-passing paradigm when developing application software. The single shared bus system has been extended to multiple buses to connect multiple processors.
A multiple bus multiprocessor system uses several parallel buses to interconnect multiple processors and multiple memory modules. A number of connection schemes are possible in this case. Among the possibilities are the multiple bus with full bus–memory connection (MBFBMC), multiple bus with single bus memory connection (MBSBMC), multiple bus with partial bus–memory connection (MBPBMC), and multiple bus with class-based memory connection (MBCBMC). The multiple bus with full bus–memory connection has all memory modules connected to all buses. The multiple bus with single bus–memory connection has each memory module connected to a specific bus. The multiple bus with partial bus–memory connection has each memory module connected to a subset of buses. The multiple bus with class-based memory connection has memory modules grouped into classes whereby each class is connected to a specific subset of buses. A class is just an arbitrary collection of memory modules.
A typical bus-based design uses caches to solve the bus contention problem. Highspeed caches connected to each processor on one side and the bus on the other side mean that local copies of instructions and data can be supplied at the highest possible rate. If the local processor finds all of its instructions and data in the local cache, we say the hit rate is 100%. The miss rate of a cache is the fraction of the references that are not stored locally. The required data must be copied from the global memory, across the bus and into the cache. From there it is routed to the local processor. One of the goals of the cache is to maintain a low miss rate under high processor loads. A low miss rate means the processors do not have to use the bus as much. Miss rates are determined by a number of factors, ranging from the complexity and number of applications being run to the organization of the cache hardware that is implemented.
Current High End SMPs
Symmetric multiprocessors (SMPs) are available from a wide range of workstation vendors in various configurations. With the introduction of dual-core devices, SMP is found in most new desktop machines and in many laptop machines. The most popular entry-level SMP systems use the x86 instruction set architecture and are based on Intel’s Xeon, Pentium D, Core Duo, and Core 2 Duo based processors or AMD’s Athlon64 X2, Quad FX or Opteron 200 and 2000 series processors. Servers use those processors and other readily available non-x86 processor choices including the Sun Microsystems UltraSPARC, Fujitsu SPARC64, SGI MIPS, Intel Itanium, Hewlett Packard PA-RISC, Hewlett-Packard (formerly Compaq formerly Digital Equipment Corporation) DEC Alpha, IBM POWER and Apple Computer PowerPC (specifically G4 and G5 series, as well as earlier PowerPC 604 and 604e series) processors.
1. The Sun Fire 12K server is a high-end data center server with up to 52 UltraSPARC III Cu 1.2-GHz processors in a symmetric multiprocessing architecture. The Sun Fire E52K server scales up to 72 UltraSPARC IV+ processors.
2. The Cray XT4 system can scale from 562 to 30,614 AMD Dual Core 2.6-GHz giving a peak performance varying from 5.6TFLOPS to 318 TFLOPS.
3. The IBM System p5 595 server uses fifth-generation 64-bit IBM POWER5 technology in up to 64 core symmetric multi-processing (SMP) configurations with IBM Advanced POWER5+ (2.1/2.3GHz).
Evolution of Supercomputers
Since the Cray T3E, supercomputers have steadily improved their shared address space architectures. Many of the improvements in address space organization have been utilized by supercomputers. Since the T3E was released, Cray merged with SGI and acquired OctigaBay Systems Corporation. As a leader in the development of supercomputers, Cray, Inc. has released several more machines superior to the T3E. The most noticeable feature in newer supercomputers is the implementation of distributed shared memory (DSM). The DSM architecture removes memory contention and interconnect bottlenecks by giving all processors equal access times to all memory locations.
Unlike most other systems, the Cray X1E system has a DSM architecture that integrates the memory and interconnect subsystems to allow memory references to be efficiently routed directly to the appropriate local or remote memory. Memory is physically distributed on individual modules, but all memory is directly addressable to and accessible by any MSP (multi-streaming processor) in the system through the use of load and store instructions. While each node functions like a traditional SMP(symmetric multiprocessor) node, its processors can also directly address memory on any other node—remote memory accesses go over the interconnect to request processors, bypassing the local cache. This mechanism is more scalable than traditional shared memory and it provides very low latencies and unprecedented interprocessor bandwidths. Each processor can have up to 2,048 outstanding memory references, allowing applications to tolerate global network latencies.
The interconnect supporting these remote references includes routing logic and network ports on each compute module, and separate routing modules. A novel design effectively implements 16 independent 2D torus topologies within the interconnect, each called a slice. Processor or I/O memory references are first handled by the routing logic of the appropriate slice. If the address is local to the node, the routing logic accesses the node’s local memory. If the memory address is on a remote node, the request is routed using the network, and the routing logic on the remote node handles the request as a local reference. Each slice of the machine independently handles all memory accesses and routing for addresses that map to that slice. Each compute module accesses the network through a total of 32 network ports, two per slice, each of which supports 1.6 GB/second peak per direction. For large systems, half of these ports are connected to router modules which are connected to other compute or router modules to build up the interconnect. The scalability of this interconnect is further enhanced by the following features. Local memory references are cached, remote memory references are not, reducing the overhead normally associated with SMP coherence protocols. The Cray X1E system translates addresses at the destination node, requiring each node only keep track of translation information for its local memory.
References
[1] Sunfire12k
[2] Cray XT4
[3] IBM
[4] Cray X1E
[5] Wikipedia: Vector Processor
6. McCurdy , C. & Fischer, C. (2003). User-controllable coherence for high performance shared memory multiprocessors. Proceedings of the Ninth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming Archive, , 73-82.
7. Culler, D. E., Singh, J. P., & Gupta, A. (1999). Introduction: Convergence of Parallel Architectures: Shared Address Space. In D. E. Penrose (Ed.), A Tutor's Guide: Helping Writers One to One (pp. 28-37). San Francisco, CA: Morgan Kaufmann.
8. El-Rewini, Hesham. Abd-El-Barr, Mostafa. Advanced Computer Architecture and Parallel Processing (chapter 2 & 4), John Wiley & Sons, Inc. (US), 2005