CSC/ECE 506 Fall 2007/wiki3 1 satkar: Difference between revisions
No edit summary |
|||
| (23 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
== ''Topic for Discussion'' == | |||
True and false sharing. In Lectures 9 and 10, we covered performance results for true- and false-sharing misses. The results showed that some applications experienced degradation due to false sharing, and that this problem was greater with larger cache lines. But these data are at least 9 years old, and for multiprocessors that are smaller than those in use today. Comb the ACM Digital Library, IEEE Xplore, and the Web for more up-to-date results. What strategies have proven successful in combating false sharing? Is there any research into ways of diminishing true-sharing misses, e.g., by locating communicating processes on the same processor? Wouldn't this diminish parallelism and thus hurt performance? | |||
== ''Introduction'' == | == ''Introduction'' == | ||
The cache organization plays a key role in the modern computers, especially in the multiprocessors. As we scale the number of processors, subsequently the cache miss rate also increases. The high cache miss rate is a cause of concern, since it can significantly limit the performance of multiprocessors. The cache misses are broadly categorized into “Three-Cs”, namely Compulsory misses, Capacity misses and the Conflict misses. There is yet another category of misses introduced by the cache coherent multiprocessors, called the coherence misses. These occur when blocks of data are shared among multiple caches, and are of two types; | The cache organization plays a key role in the modern computers, especially in the multiprocessors. As we scale the number of processors, subsequently the cache miss rate also increases. The high cache miss rate is a cause of concern, since it can significantly limit the performance of multiprocessors. The cache misses are broadly categorized into “Three-Cs”, namely Compulsory misses, Capacity misses and the Conflict misses. There is yet another category of misses introduced by the cache coherent multiprocessors, called the coherence misses. These occur when blocks of data are shared among multiple caches, and are of two types; | ||
• '''True sharing''': When a data word produced by a processor is used by another processor, then it is said to be True Sharing. True sharing is intrinsic to a particular memory reference stream of a program and is not dependent on the block size. | • '''True sharing''': When a data word produced by a processor is used by another processor, then it is said to be True Sharing. True sharing is intrinsic to a particular memory reference stream of a program and is not dependent on the block size.True sharing requires the processors involved to explicitly synchronize with each other to ensure program correctness. A computation is said to have temporal locality if it re-uses much of the data it has been accessing; programs with high temporal locality tend to have less true sharing. The amount of true sharing in the program is a critical factor for performance on multiprocessors; high levels of true sharing and synchronization can easily overwhelm the advantage of parallelism. | ||
• '''False Sharing''': | • '''False Sharing''': False sharing occurs when two or more processors access(and at least one of them writes) different data elements in the same coherence unit (cache line, memory page, etc.) . A severe form of false sharing occurs when an array dimension | ||
that exhibits spatial reuse is accessed by multiple writers, i.e., multiple processors that write to data in the same coherence | |||
unit. For example, this form of false sharing might occur when each processor updates a different row of a two-dimensional array stored in column-major order. | |||
Increasing the size of the line in the cache helps in reducing the hit time, as more blocks can be accommodated in the same line. However, long cache lines may cause false sharing, when different processors access different words in the same cache line. In essence, they share the same line, without truly sharing the accessed data. | Increasing the size of the line in the cache helps in reducing the hit time, as more blocks can be accommodated in the same line. However, long cache lines may cause false sharing, when different processors access different words in the same cache line. In essence, they share the same line, without truly sharing the accessed data. | ||
==''Problem with False Sharing'' == | ==''Problem with False Sharing'' == | ||
In multiprocessors, accessing a memory location causes a slice of actual memory (a cache line) containing the memory location requested to be copied into the cache.Subsequent references to the same memory location or those around it can probably be satisfied out of the cache until the system determines it is necessary to maintain the coherency between cache and memory and restore the cache line back to memory. | In multiprocessors, accessing a memory location causes a slice of actual memory (a cache line) containing the memory location requested to be copied into the cache.Subsequent references to the same memory location or those around it can probably be satisfied out of the cache until the system determines it is necessary to maintain the coherency between cache and memory and restore the cache line back to memory. | ||
| Line 17: | Line 21: | ||
But, in a scenario, where multiple processors try to update individual elements in the same cache line, the entire cache line is invalidated, even though the updates are independent of each other.Each update of an individual element of a cache line marks the line as invalid. Hence, other processors accessing a different element in the same line see the line marked as invalid. They are forced to fetch a fresh copy of the line from memory, even though the element accessed has not been modified. This is because cache coherency is maintained on a cache-line basis, and not for individual elements. As a result there will be an increase in interconnect traffic and overhead. Also, while the cache-line update is in progress, access to the elements in the line is inhibited. This situation is called false sharing, and might become a bottleneck in the path of performance and scalability. | But, in a scenario, where multiple processors try to update individual elements in the same cache line, the entire cache line is invalidated, even though the updates are independent of each other.Each update of an individual element of a cache line marks the line as invalid. Hence, other processors accessing a different element in the same line see the line marked as invalid. They are forced to fetch a fresh copy of the line from memory, even though the element accessed has not been modified. This is because cache coherency is maintained on a cache-line basis, and not for individual elements. As a result there will be an increase in interconnect traffic and overhead. Also, while the cache-line update is in progress, access to the elements in the line is inhibited. This situation is called false sharing, and might become a bottleneck in the path of performance and scalability. | ||
== Strategies to | == ''Strategies to combat False Sharing'' == | ||
Several strategies have been proposed and are been worked up on in order to decrease false sharing in multi processor. This article would try to introduce a few of the salient ones. | Several strategies have been proposed and are been worked up on in order to decrease false sharing in multi processor. This article would try to introduce a few of the salient ones. | ||
* Reducing False Sharing through Proper Block Sizing | * Reducing False Sharing through Proper Block Sizing | ||
* Reducing False Sharing through Sectored Caches | |||
* Reducing False Sharing through Optimizing the Layout of Shared Data in Cache Blocks | * Reducing False Sharing through Optimizing the Layout of Shared Data in Cache Blocks | ||
* Reducing False Sharing through Compile Time Data Transformations | * Reducing False Sharing through Compile Time Data Transformations | ||
* | * Dynamic Cache Sub-Block Design to Reduce False Sharing | ||
* False Sharing Elimination by Selection of Runtime Scheduling Parameters | |||
This article explores some of the above issues, and the links, that would deal with the last two techniques stated above, have been provided in the references section below. | |||
=== | === Proper Block Sizing === | ||
An algorithm can be designed to select the block sizes, to minimize bus traffic through the use of variable (static) size blocks; i.e., the block size choice varies over the memory space of the program, but any given word is assigned to a specific fixed block size for the entire program execution. Starting with each word in the memory space that is used, neighboring blocks are combined. If when combined they produce less bus traffic than when left as single blocks. When neighboring words have similar access patterns and it is useful to prefetch one while demand fetching the other, the traffic is reduced when the words (or blocks) are grouped into a single unit due to fewer address transmissions over the bus. When excessive traffic is generated due to false sharing, the problem blocks are isolated by not combining them into larger units. | An algorithm can be designed to select the block sizes, to minimize bus traffic through the use of variable (static) size blocks; i.e., the block size choice varies over the memory space of the program, but any given word is assigned to a specific fixed block size for the entire program execution. Starting with each word in the memory space that is used, neighboring blocks are combined. If when combined they produce less bus traffic than when left as single blocks. When neighboring words have similar access patterns and it is useful to prefetch one while demand fetching the other, the traffic is reduced when the words (or blocks) are grouped into a single unit due to fewer address transmissions over the bus. When excessive traffic is generated due to false sharing, the problem blocks are isolated by not combining them into larger units. | ||
=== | === Sectored Caches === | ||
Sectored caches, can yet be another effective strategy to reduce the false sharing misses, in bus based multiprocessors. The sectored cache is organized such that each line is divided into basic coherence units, called subblocks. When a false sharing occurs, the involved cache line need not be invalidates or transferred, as long as the corresponding subblocks are kept coherent. Simulations on this strategy have helped in effectively reducing false sharing misses by about 30-80%. details regarding the simulation are explained in the paper linked below. | |||
[http://citeseer.ist.psu.edu/cache/papers/cs/5048/ftp:zSzzSzpads10.cs.nthu.edu.twzSzpubzSzpaperszSzkcliuzSzicpads97.pdf/liu97effectiveness.pdf] Sectored Caches | |||
=== Optimizing the Layout of Shared Data in Cache Blocks === | |||
A very important parameter that affects false sharing, is the block size in a cache. An increase in the block size in case of uniprocessors tends to increase the spatial locality due to which the miss rate decreases. Where as in case of multiprocessors, increase in block size not only increases spatial locality but also increases the probability of false sharing. Thus the miss rate due to increased block size can go up or down in multiprocessors. The graph below shows the variations of miss rate as a function of the block size, done with respect to 16 and 32 processors. It depicts the significant increment in the miss rate as the block size increases, due to false sharing. | A very important parameter that affects false sharing, is the block size in a cache. An increase in the block size in case of uniprocessors tends to increase the spatial locality due to which the miss rate decreases. Where as in case of multiprocessors, increase in block size not only increases spatial locality but also increases the probability of false sharing. Thus the miss rate due to increased block size can go up or down in multiprocessors. The graph below shows the variations of miss rate as a function of the block size, done with respect to 16 and 32 processors. It depicts the significant increment in the miss rate as the block size increases, due to false sharing. | ||
| Line 50: | Line 64: | ||
False sharing is caused by a mismatch between the memory layout of the write-shared data and the cross-processor memory reference pattern to it. Manually changing the placement of this data to better conform to the memory reference pattern can reduce false sharing up to 75%. | False sharing is caused by a mismatch between the memory layout of the write-shared data and the cross-processor memory reference pattern to it. Manually changing the placement of this data to better conform to the memory reference pattern can reduce false sharing up to 75%. | ||
=== | === Compile Time Data Transformations === | ||
This section, introduces to the reader, the concepts of compile time data transformations. in order to achieve reduced false sharing multiprocessors. Referring to Paper by Tor E. Jeremiassen and Susan J. Eggers, would give a detailed explanation of the algorithms. | |||
A series of compiler directed algorithms and a suite of transformations can be employed, that restructure the shared data at compile time. These algorithms analyze explicitly parallel programs, producing information about their cross-processor memory reference patterns, that identifies data structures susceptible to false sharing, and then chooses appropriate transformations to eliminate it. | |||
The compiler analysis comprises of the following three stages; | |||
* Determination of the section of code, each process executes by computing its control flow graph (per-process control flow analysis). | |||
* Performing non-concurrency analysis, by examining the barrier synchronization pattern of the program, delineating the phases that cannot execute in parallel and computing the flow of control between them. | |||
* Performing a summary side-effect analysis, on a per-process basis for each phase (determined in stage two). | |||
The per-processor control flow analysis and summary side-effect analysis (Stages 1 and 3 respectively), yields the sections of shared data that each processor reads and writes.The non-concurrency analysis (stage – 2), uses synchronization points to determine which portions of the code can execute in parallel and which cannot. | |||
In order to reduce the number of false sharing misses, data must be restructured so that: | |||
* Data that is only, or overwhelmingly, accessed by one processor is grouped together. | |||
* Write shared data objects with no processor locality do not share cache lines. | |||
Two transformations have been devised to achieve the above to conditions. | |||
* '''group and transpose''' – To address condition 1. | |||
* '''padding''' – To address condition 2. | |||
Group and transpose physically group data together by changing the layout of the data structures in memory. If each processor’s data is less than the cache block size, it may be padded so that no two processor's data share a cache block. In addition to avoiding false sharing, this also improves spatial locality. | |||
The second transformation, padding pads data that is falsely shared in the short term but eventually write shared by all processors over time. | |||
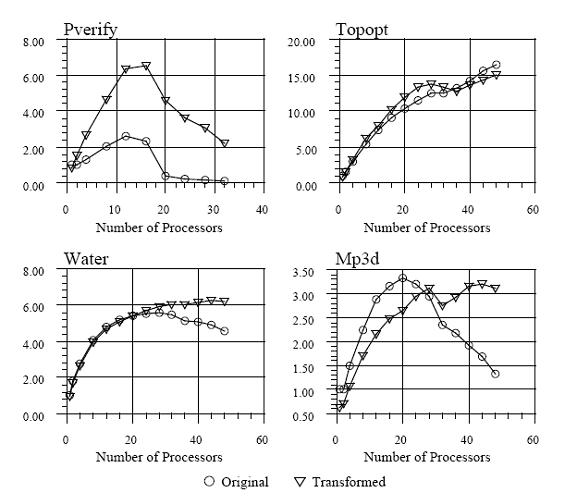
The speedups achieved with the compile time data transformations for a few test programs are given below. | |||
[[Image:Plots.jpg]] | |||
== Diminishing True sharing misses == | |||
A new technique, called coherence de-coupling, breaks a traditional cache coherence protocol into two protocols: a Speculative Cache Lookup SCL)protocol and a safe, backing coherence protocol. The SCL protocol produces a speculative load value, typically from an invalid cache line, permitting the processor to compute with incoherent data. In parallel, the coherence protocol obtains the necessary coherence permissions and the correct value. Eventually, the speculative use of the incoherent data can be verified against the coherent data. Thus,coherence decoupling can greatly reduce if not eliminate the effects of false sharing. Furthermore, coherence decoupling can also reduce latencies incurred by true sharing. The simulations and results can be viewed at the link below. | |||
[ftp://ftp.cs.utexas.edu/pub/dburger/papers/ASPLOS04_cd.pdf] | |||
==''References''== | ==''References''== | ||
| Line 60: | Line 103: | ||
[http://iacoma.cs.uiuc.edu/iacoma-papers/false_sharing.pdf] | [http://iacoma.cs.uiuc.edu/iacoma-papers/false_sharing.pdf] | ||
False Sharing and Spatial Locality in Multiprocessor Caches | False Sharing and Spatial Locality in Multiprocessor Caches | ||
Josep Torrellas, Member, IEEE, Mbnica S. Lam, Member, IEEE, and John L. Hennessy, Fellow, IEEE | Josep Torrellas, Member, IEEE, Mbnica S. Lam, Member, IEEE, and John L. Hennessy, Fellow, IEEE | ||
[http://www.eecs.berkeley.edu/Pubs/TechRpts/1999/CSD-99-1064.pdf] | [http://www.eecs.berkeley.edu/Pubs/TechRpts/1999/CSD-99-1064.pdf] | ||
Analysis of Shared Memory Misses and Reference Patterns | Analysis of Shared Memory Misses and Reference Patterns | ||
Jeffrey B. Rothman and Alan Jay Smith | Jeffrey B. Rothman and Alan Jay Smith | ||
[http://coblitz.codeen.org:3125/citeseer.ist.psu.edu/cache/papers/cs/1663/ftp:zSzzSzftp.cs.washington.eduzSztrzSz1994zSz09zSzUW-CSE-94-09-05.pdf/jeremiassen94reducing.pdf] | [http://coblitz.codeen.org:3125/citeseer.ist.psu.edu/cache/papers/cs/1663/ftp:zSzzSzftp.cs.washington.eduzSztrzSz1994zSz09zSzUW-CSE-94-09-05.pdf/jeremiassen94reducing.pdf] | ||
Reducing False Sharing on Shared Memory Multiprocessors through Compile Time Data Transformations. | Reducing False Sharing on Shared Memory Multiprocessors through Compile Time Data Transformations. | ||
Tor E. Jeremiassen and Susan J. Eggers | Tor E. Jeremiassen and Susan J. Eggers | ||
[https://www.it.uu.se/research/publications/reports/2003-044/2003-044-nc.pdf] | |||
Cache Memory Behavior of Advanced PDE Solvers | |||
[http://citeseer.ist.psu.edu/cache/papers/cs/26601/http:zSzzSzresearch.cs.tamu.eduzSzncstrlzSzTR95-010.pdf/kadiyala95dynamic.pdf] | |||
A Dynamic Cache Sub-Block Design to Reduce False Sharing | |||
Murali Kadiyala and Laxmi N Bhuyan | |||
[http://citeseer.ist.psu.edu/cache/papers/cs/573/http:zSzzSzwww.csg.lcs.mit.edu:8001zSzUserszSzvivekzSz.zSzpszSzChSa97.pdf/chow97false.pdf] | |||
False Sharing Elimination by Selection of Runtime Scheduling Parameters | |||
Jyh-Herng Chow and Vivek Sarkar | |||
Latest revision as of 00:28, 25 October 2007
Topic for Discussion
True and false sharing. In Lectures 9 and 10, we covered performance results for true- and false-sharing misses. The results showed that some applications experienced degradation due to false sharing, and that this problem was greater with larger cache lines. But these data are at least 9 years old, and for multiprocessors that are smaller than those in use today. Comb the ACM Digital Library, IEEE Xplore, and the Web for more up-to-date results. What strategies have proven successful in combating false sharing? Is there any research into ways of diminishing true-sharing misses, e.g., by locating communicating processes on the same processor? Wouldn't this diminish parallelism and thus hurt performance?
Introduction
The cache organization plays a key role in the modern computers, especially in the multiprocessors. As we scale the number of processors, subsequently the cache miss rate also increases. The high cache miss rate is a cause of concern, since it can significantly limit the performance of multiprocessors. The cache misses are broadly categorized into “Three-Cs”, namely Compulsory misses, Capacity misses and the Conflict misses. There is yet another category of misses introduced by the cache coherent multiprocessors, called the coherence misses. These occur when blocks of data are shared among multiple caches, and are of two types;
• True sharing: When a data word produced by a processor is used by another processor, then it is said to be True Sharing. True sharing is intrinsic to a particular memory reference stream of a program and is not dependent on the block size.True sharing requires the processors involved to explicitly synchronize with each other to ensure program correctness. A computation is said to have temporal locality if it re-uses much of the data it has been accessing; programs with high temporal locality tend to have less true sharing. The amount of true sharing in the program is a critical factor for performance on multiprocessors; high levels of true sharing and synchronization can easily overwhelm the advantage of parallelism.
• False Sharing: False sharing occurs when two or more processors access(and at least one of them writes) different data elements in the same coherence unit (cache line, memory page, etc.) . A severe form of false sharing occurs when an array dimension that exhibits spatial reuse is accessed by multiple writers, i.e., multiple processors that write to data in the same coherence unit. For example, this form of false sharing might occur when each processor updates a different row of a two-dimensional array stored in column-major order.
Increasing the size of the line in the cache helps in reducing the hit time, as more blocks can be accommodated in the same line. However, long cache lines may cause false sharing, when different processors access different words in the same cache line. In essence, they share the same line, without truly sharing the accessed data.
Problem with False Sharing
In multiprocessors, accessing a memory location causes a slice of actual memory (a cache line) containing the memory location requested to be copied into the cache.Subsequent references to the same memory location or those around it can probably be satisfied out of the cache until the system determines it is necessary to maintain the coherency between cache and memory and restore the cache line back to memory.
But, in a scenario, where multiple processors try to update individual elements in the same cache line, the entire cache line is invalidated, even though the updates are independent of each other.Each update of an individual element of a cache line marks the line as invalid. Hence, other processors accessing a different element in the same line see the line marked as invalid. They are forced to fetch a fresh copy of the line from memory, even though the element accessed has not been modified. This is because cache coherency is maintained on a cache-line basis, and not for individual elements. As a result there will be an increase in interconnect traffic and overhead. Also, while the cache-line update is in progress, access to the elements in the line is inhibited. This situation is called false sharing, and might become a bottleneck in the path of performance and scalability.
Strategies to combat False Sharing
Several strategies have been proposed and are been worked up on in order to decrease false sharing in multi processor. This article would try to introduce a few of the salient ones.
- Reducing False Sharing through Proper Block Sizing
- Reducing False Sharing through Sectored Caches
- Reducing False Sharing through Optimizing the Layout of Shared Data in Cache Blocks
- Reducing False Sharing through Compile Time Data Transformations
- Dynamic Cache Sub-Block Design to Reduce False Sharing
- False Sharing Elimination by Selection of Runtime Scheduling Parameters
This article explores some of the above issues, and the links, that would deal with the last two techniques stated above, have been provided in the references section below.
Proper Block Sizing
An algorithm can be designed to select the block sizes, to minimize bus traffic through the use of variable (static) size blocks; i.e., the block size choice varies over the memory space of the program, but any given word is assigned to a specific fixed block size for the entire program execution. Starting with each word in the memory space that is used, neighboring blocks are combined. If when combined they produce less bus traffic than when left as single blocks. When neighboring words have similar access patterns and it is useful to prefetch one while demand fetching the other, the traffic is reduced when the words (or blocks) are grouped into a single unit due to fewer address transmissions over the bus. When excessive traffic is generated due to false sharing, the problem blocks are isolated by not combining them into larger units.
Sectored Caches
Sectored caches, can yet be another effective strategy to reduce the false sharing misses, in bus based multiprocessors. The sectored cache is organized such that each line is divided into basic coherence units, called subblocks. When a false sharing occurs, the involved cache line need not be invalidates or transferred, as long as the corresponding subblocks are kept coherent. Simulations on this strategy have helped in effectively reducing false sharing misses by about 30-80%. details regarding the simulation are explained in the paper linked below.
[1] Sectored Caches
A very important parameter that affects false sharing, is the block size in a cache. An increase in the block size in case of uniprocessors tends to increase the spatial locality due to which the miss rate decreases. Where as in case of multiprocessors, increase in block size not only increases spatial locality but also increases the probability of false sharing. Thus the miss rate due to increased block size can go up or down in multiprocessors. The graph below shows the variations of miss rate as a function of the block size, done with respect to 16 and 32 processors. It depicts the significant increment in the miss rate as the block size increases, due to false sharing.
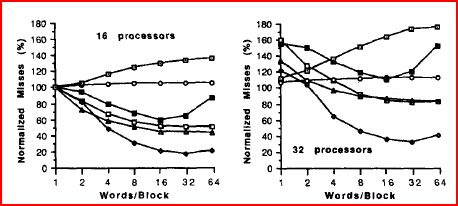

Different data placement optimizations have been suggested to improve the miss rate due to false sharing. They are listed below.
- SplitScalar: Place scalar variables that cause false sharing in different blocks.
- Heap Allocate: Allocate shared space from different heap regions according to which processor request the space. It is common for a slave process to access the shared space that it requests itself. If no action is taken, the space allocated by different processes may share the same cache block and lead to false sharing.
- Expand Record: Expand records in an array (padding with dummy words) to reduce the sharing of a cache block by different records. While successful prefetching may occur within a record or across records, false sharing usually occurs across records, when more than one of them share the same cache block.
- Align Record: Choose a layout for arrays of records that minimizes the number of blocks the average record spans. This optimization maximizes prefetching of the rest of the record when one word of a record is accessed, and may also reduce false sharing.
- Lockscalar: Place active scalars that are protected by a lock in the same block as the lock variable. As a result, the scalar is prefetched when the lock is accessed.
False sharing is caused by a mismatch between the memory layout of the write-shared data and the cross-processor memory reference pattern to it. Manually changing the placement of this data to better conform to the memory reference pattern can reduce false sharing up to 75%.
Compile Time Data Transformations
This section, introduces to the reader, the concepts of compile time data transformations. in order to achieve reduced false sharing multiprocessors. Referring to Paper by Tor E. Jeremiassen and Susan J. Eggers, would give a detailed explanation of the algorithms.
A series of compiler directed algorithms and a suite of transformations can be employed, that restructure the shared data at compile time. These algorithms analyze explicitly parallel programs, producing information about their cross-processor memory reference patterns, that identifies data structures susceptible to false sharing, and then chooses appropriate transformations to eliminate it.
The compiler analysis comprises of the following three stages;
- Determination of the section of code, each process executes by computing its control flow graph (per-process control flow analysis).
- Performing non-concurrency analysis, by examining the barrier synchronization pattern of the program, delineating the phases that cannot execute in parallel and computing the flow of control between them.
- Performing a summary side-effect analysis, on a per-process basis for each phase (determined in stage two).
The per-processor control flow analysis and summary side-effect analysis (Stages 1 and 3 respectively), yields the sections of shared data that each processor reads and writes.The non-concurrency analysis (stage – 2), uses synchronization points to determine which portions of the code can execute in parallel and which cannot.
In order to reduce the number of false sharing misses, data must be restructured so that:
- Data that is only, or overwhelmingly, accessed by one processor is grouped together.
- Write shared data objects with no processor locality do not share cache lines.
Two transformations have been devised to achieve the above to conditions.
- group and transpose – To address condition 1.
- padding – To address condition 2.
Group and transpose physically group data together by changing the layout of the data structures in memory. If each processor’s data is less than the cache block size, it may be padded so that no two processor's data share a cache block. In addition to avoiding false sharing, this also improves spatial locality.
The second transformation, padding pads data that is falsely shared in the short term but eventually write shared by all processors over time.
The speedups achieved with the compile time data transformations for a few test programs are given below.

Diminishing True sharing misses
A new technique, called coherence de-coupling, breaks a traditional cache coherence protocol into two protocols: a Speculative Cache Lookup SCL)protocol and a safe, backing coherence protocol. The SCL protocol produces a speculative load value, typically from an invalid cache line, permitting the processor to compute with incoherent data. In parallel, the coherence protocol obtains the necessary coherence permissions and the correct value. Eventually, the speculative use of the incoherent data can be verified against the coherent data. Thus,coherence decoupling can greatly reduce if not eliminate the effects of false sharing. Furthermore, coherence decoupling can also reduce latencies incurred by true sharing. The simulations and results can be viewed at the link below.
References
[3] False Sharing and Spatial Locality in Multiprocessor Caches
Josep Torrellas, Member, IEEE, Mbnica S. Lam, Member, IEEE, and John L. Hennessy, Fellow, IEEE
[4] Analysis of Shared Memory Misses and Reference Patterns
Jeffrey B. Rothman and Alan Jay Smith
[5] Reducing False Sharing on Shared Memory Multiprocessors through Compile Time Data Transformations.
Tor E. Jeremiassen and Susan J. Eggers
[6] Cache Memory Behavior of Advanced PDE Solvers
[7] A Dynamic Cache Sub-Block Design to Reduce False Sharing
Murali Kadiyala and Laxmi N Bhuyan
[8] False Sharing Elimination by Selection of Runtime Scheduling Parameters
Jyh-Herng Chow and Vivek Sarkar